数据库不再只是记录事实:PhoebeDB国内首秀,21倍性能与MLIR架构重构AI时代数据底座
智能,正在从概念走向生产。
在2026移动云大会上,中国移动以“移动云 智能新空间”为主题,展示AI时代云、算力、应用与产业生态的新进展。
当AI Agent开始进入企业流程,一个底层问题随之出现:智能持续运行时,什么样的数据底座才能托住它?
在此次大会上,云和恩墨携“存算管用”全栈产品亮相特装展区。其中,面向AI时代的新一代数据库底座PhoebeDB首次在国内公开亮相。
这一次亮相,传递出的不只是一个新产品信息。它指向的是一个正在发生的变化:数据库正在从记录事实的系统,走向支撑AI Agent执行、记忆、判断和审计的认知基座。
在大会的“全栈可信 数智新生——AI原生数据库技术创新沙龙”圆桌论坛环节,云和恩墨解决方案专家江宁分享了关于AI原生时代数据库发展的观察与思考:AI原生数据库应作为持久化AI Agent的“认知基座”,提供关系型状态、向量存储、追踪数据的跨类型原子性,支持快照一致推理与因果审计。PhoebeDB正通过技术验证与场景适配,推进这一理念落地发展。

图1:江宁(右二)在移动云大会相关圆桌论坛上发言
一
AI Agent正在改变数据库的角色
过去,企业应用更多是在记录人的决策。
采购员录入订单,销售人员提交客户信息,财务人员确认付款,运维人员记录故障处理。人的判断通常发生在系统之外,应用负责记录结果,数据库负责保存结果。
AI Agent进入之后,边界开始变化:应用软件开始参与决策的形成。
例如,一张采购订单过去可能来自采购员根据库存、价格、交期和经验做出的判断。未来,采购Agent可能会持续读取库存状态、历史消耗、供应商交付能力、价格变化、生产计划和风险约束,自动比较多个采购方案,形成推荐决策,并触发后续流程。
这时,数据库要保存的不只是“采购订单”这个结果,还要保存决策基于哪些事实、比较过哪些方案、使用了哪些约束、中间状态如何变化、最终结果如何形成,以及出现争议时能否追踪和回放。
因此,AI时代的数据库正在从企业系统的“事实仓库”,走向AI Agent的工作记忆与证据系统。它既要支撑Agent持续读取、比较、判断和更新状态,也要让这些判断在事后能够被追踪、被审计、被回放。
这就是“认知基座”的真正含义:它让智能体在企业系统中持续运行时,拥有一个稳定、一致、可追踪的数据基础。
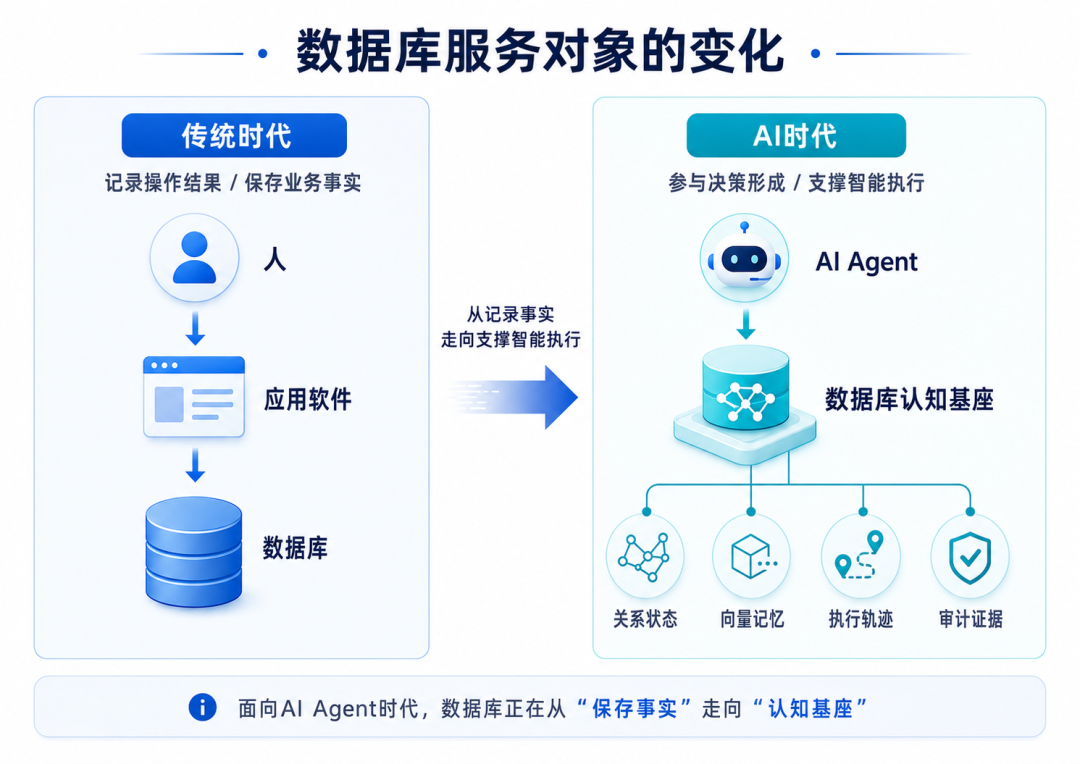
图2:数据库服务对象正在从“人-应用软件-数据库”,
演进为“AI Agent-数据库认知基座-多类型数据能力”
二
PhoebeDB:面向AI时代的新一代数据库底座
PhoebeDB不是给数据库增加一个AI标签,而是让关系状态、向量记忆和执行轨迹进入同一个可信数据底座。
PhoebeDB是云和恩墨面向AI时代推出的数据库内核级创新成果。
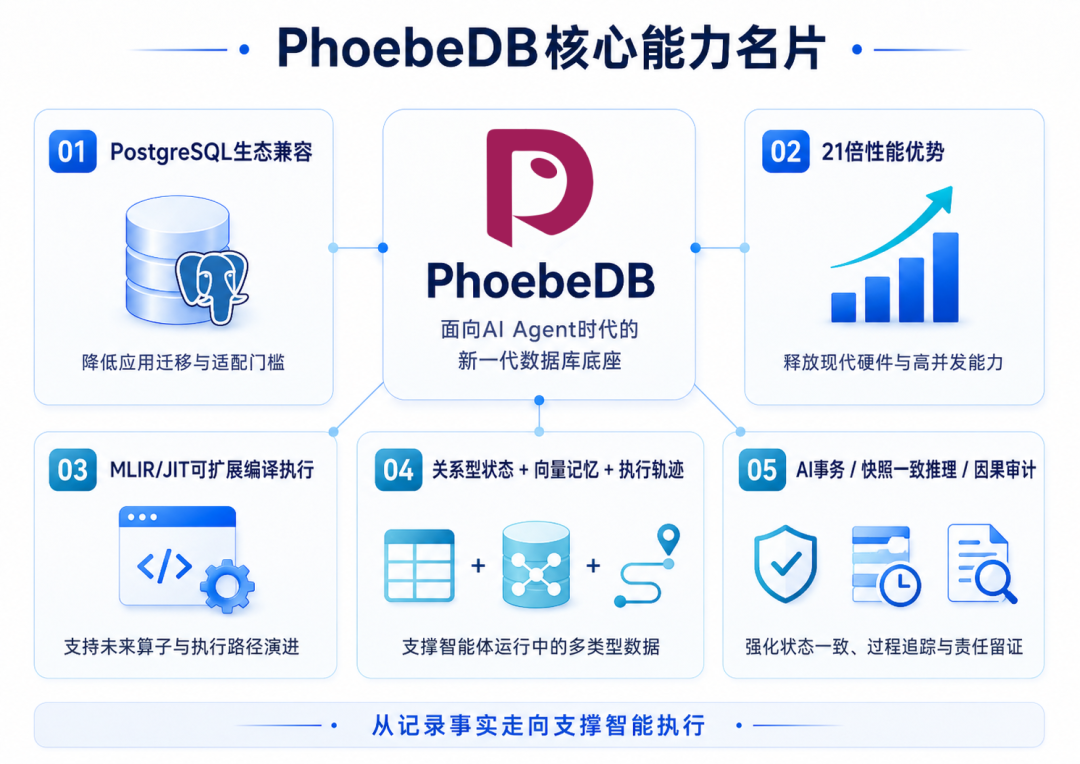
图3:PhoebeDB面向AI Agent时代的核心能力结构
它从底层架构出发,面向现代硬件、高并发OLTP和AI原生场景重新设计,既关注关系数据库必须具备的强一致与SQL能力,也面向向量记忆、AI事务、快照一致推理与因果审计等新需求持续演进。
|
PhoebeDB 技术名片 |
|
|
产品定位 |
面向AI Agent时代的新一代数据库底座 |
|
兼容方向 |
面向PostgreSQL生态兼容设计 |
|
核心性能 |
基于TPC-C模型测试,单机达到千万级tpmC,较同等资源条件下PostgreSQL 17展现约21倍性能优势 |
|
执行架构 |
内存中心架构、协程化执行、智能Pull式调度、MLIR/JIT编译路径 |
|
AI能力方向 |
关系型状态、向量记忆、执行轨迹、跨类型原子性、快照一致推理、因果审计 |
|
长期价值 |
支撑AI Agent持续运行中的状态管理、过程追踪与可信执行 |
PhoebeDB关注一个底层问题:当AI Agent持续运行时,关系状态、向量记忆和执行轨迹,能否在同一个可信数据底座中保持一致?
这也是AI事务能力的关键。
在一次Agent任务中,系统可能需要同时更新关系型业务状态、向量型长期记忆和因果审计轨迹。
例如,一个采购Agent形成订单建议时,可能同时修改采购申请状态,写入供应商评估记忆,并记录本次判断所依据的库存、价格、交期和风险约束。
如果这些数据分别落在不同系统中,就可能出现业务状态已经更新、记忆尚未同步、审计轨迹缺失的情况。
PhoebeDB希望通过关系型状态、向量记忆与执行轨迹在同一事务框架下的协同管理,让Agent执行链路中的状态、记忆和证据保持一致,从而降低推理依据漂移、过程不可追踪和结果难以回放的风险。
三
21倍性能:让AI时代的数据底座跑起来
PhoebeDB此次首秀中,最容易被记住的数字,是21倍!
在基于TPC-C模型的基准测试中,PhoebeDB在通用双路中端服务器环境下,单机性能达到1028万tpmC和2360万TPM的事务吞吐能力;在相同资源和关键配置条件下,性能是PostgreSQL 17约110万TPM的21倍。在特定YCSB高并发写入负载下,性能优势最高可达30倍。
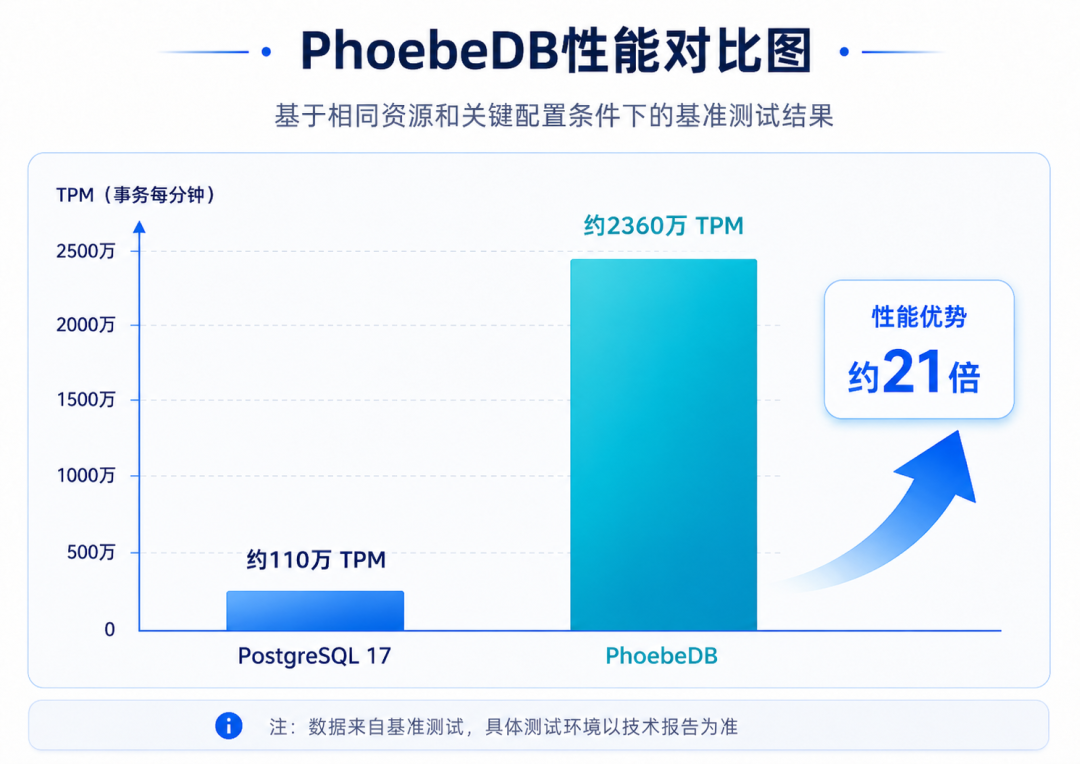
图4:基于相同资源和关键配置条件下的基准测试结果,
PhoebeDB展现出相较PG 17约21倍的性能优势
这个数字背后,更重要的是数据库底座承载能力的变化。
AI Agent带来的数据调用更高频、更连续、更自动化。数据库一旦成为Agent频繁访问的基础设施,性能问题就会变成系统稳定性、资源效率和长期成本问题。
更多CPU、更大内存、更快SSD和更多服务器,确实可以缓解一部分压力。但如果数据库内部仍然存在大量线程切换、锁竞争、解释执行开销、I/O路径瓶颈和中间结果物化,硬件能力就无法被充分释放。
PhoebeDB的方向,是重排数据库执行路径,让更多硬件能力真正用于业务计算。
这也是21倍性能背后的意义:AI时代的数据底座,可以通过执行架构重构释放效率。
四
一个高性能执行闭环:内存、调度、事务与编译
PhoebeDB要做的,不只是让数据库跑得更快,而是重排数据库执行路径,让现代硬件能力更多用于业务计算。
PhoebeDB的性能提升,不来自单点优化,而来自一组执行架构的协同。
首先,是以内存为中心的数据管理。PhoebeDB根据数据访问频率,将数据划分为热、冷、冻三层:热数据保留在内存中以实现高速访问,冷数据存放于高速存储,冻数据进行压缩归档。
这背后的思想很朴素:让高价值访问离计算更近。
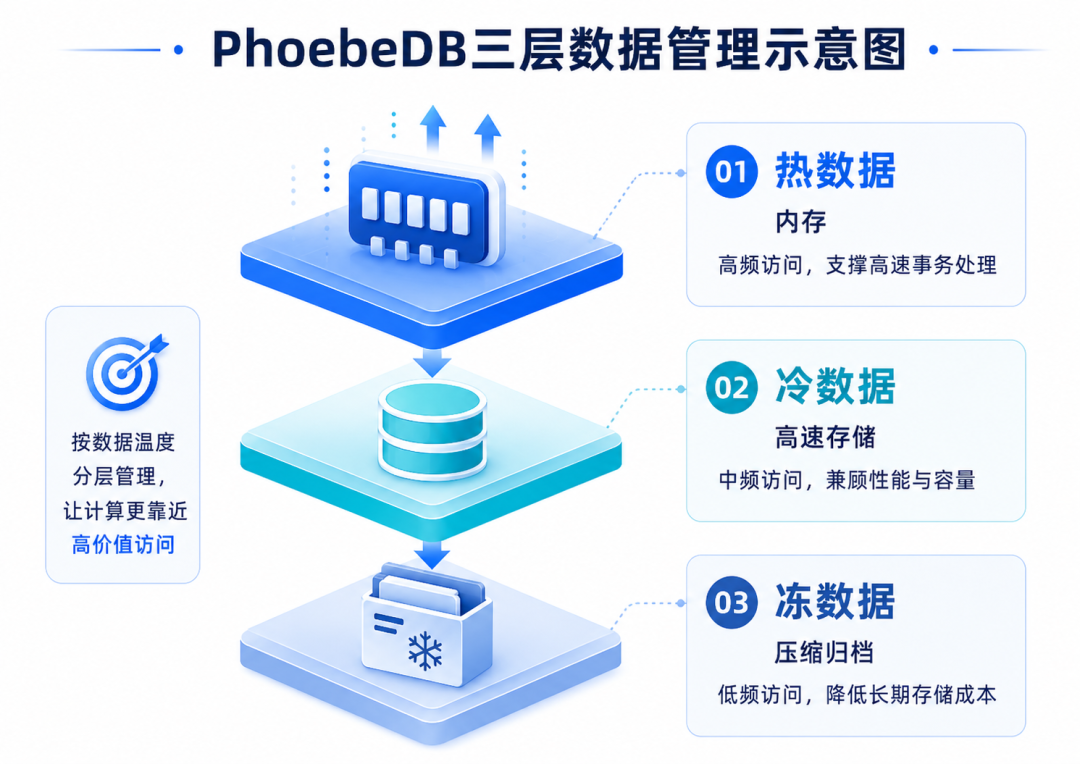
图5:PhoebeDB按数据访问温度进行分层管理,
让高价值访问更靠近计算资源
其次,是协程化执行与智能Pull式调度。
AI Agent访问数据库的方式往往更加高频、碎片化和连续。如果每一次请求都带来沉重的线程切换和锁等待,系统性能会很快被内部调度成本吞噬。协程化执行与智能Pull式调度的价值,正在于减少高并发下的无效切换和竞争,让数据库在大量Agent调用同时到来时,仍然保持更高的执行效率和资源利用率。
第三,是事务与日志机制的增强。
PhoebeDB面向PostgreSQL兼容能力设计,支持相同的事务隔离级别与锁语义,同时采用内存UNDO日志、混合并发控制、并行WAL与远程刷盘规避等技术,提升事务处理与日志吞吐能力。
在AI Agent场景下,事务与日志的意义进一步延伸。Agent形成一次决策,往往不是一个单点写入,而是一段连续执行链路:事实读取、候选方案生成、约束校验、中间状态写入、工具调用记录、最终结果提交。
UNDO日志、事务隔离和并发控制机制,可以为中间状态恢复、版本回溯和执行过程追踪提供底层支撑。
状态一致,过程可追踪,错误可回放,证据可沉淀。
五
MLIR:为未来智能负载预留架构空间
PhoebeDB近期进入LLVM/MLIR官方用户列表,也让外界多了一个观察其技术路线的窗口。
MLIR官方用户页面将PhoebeDB描述为面向生产AI Agent系统的PostgreSQL兼容HTAP数据库,并指出其使用自定义MLIR管线,将查询JIT编译为本地机器码,通过多个dialect逐级lowering到LLVM IR。
对产业用户来说,MLIR本身不是重点。重点是它背后的能力方向:数据库执行引擎需要更好的扩展性和演进能力。
今天,数据库要处理关系查询和高并发事务。明天,它可能还要处理向量记忆、Agent执行轨迹、推理上下文、审计证据链,以及新的AI算子和数据访问模式。
MLIR的价值,在于为这些变化提供一种更结构化的表达与转换机制。它让查询计划、执行算子、运行时逻辑和底层机器码之间,可以通过中间层逐级转换。新的算子、新的执行路径、新的后端适配,不必全部压到单一执行器里完成。
随着AI Infra继续演进,数据库未来可能面对GPU、NPU或其他专用加速器,也可能接入新的向量索引算法和AI算子。
对PhoebeDB而言,MLIR更像是一条面向未来负载演进的技术路径:让数据库执行路径更清晰、更可扩展,也更适合未来不断变化的智能负载。
六
“存算管用”:让数据能力形成端到端支撑
智能时代的数据能力,不可能只靠单个产品完成。数据要被存储、计算、管理和应用,还要在整个过程中保持安全、可信、可治理、可追溯。
这也是云和恩墨此次携“存算管用”全栈产品亮相的意义。
从这个视角看,PhoebeDB不是孤立的一块技术拼图,而是云和恩墨“存算管用”端到端能力中的关键底座。
数据最终要进入业务流程、智能应用和AI Agent的执行链路。PhoebeDB承担的,是其中面向AI时代的数据计算、事务处理、状态管理和可信执行能力。
当AI应用越来越多,数据调用越来越频繁,执行过程越来越复杂,数据库底座的重要性会被重新看见。

七
结语:智能越向前,数据库越要托得住
智能时代的浪潮正在展开。
云提供空间,算力提供能量,模型提供能力,应用提供场景。
但数据底座,决定了智能能不能真正进入生产。
没有一致的状态管理,AI执行就难以进入关键流程。没有可信的过程追踪,AI判断就难以被企业真正托付。没有高效的执行架构,智能应用规模化之后就会遭遇成本和性能瓶颈。
PhoebeDB的国内首秀,让AI时代的数据库被重新看见。
从21倍性能,到可扩展编译架构;从高并发事务,到AI事务与因果审计;从PostgreSQL生态兼容,到面向AI Agent的数据底座演进。
PhoebeDB正在回答一个朴素但关键的问题:当智能开始持续运行,企业需要什么样的数据库底座?
答案不会在一次首秀中全部完成。
但方向已经出现。
AI走得越远,数据底座越要托得住。
智能越向前,数据库越要稳。