GaussDB T 数据库设计优化(性能调优大全)
墨天轮原文链接:https://www.modb.pro/db/22512
1 单机&主备部署
1.1 数据表
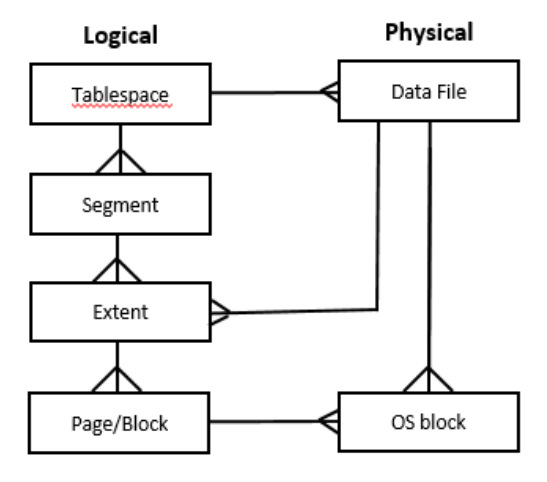
表的存储
● segemnt和extent
Segment对应一个表或索引,如果分区,则对应一个最小分区。
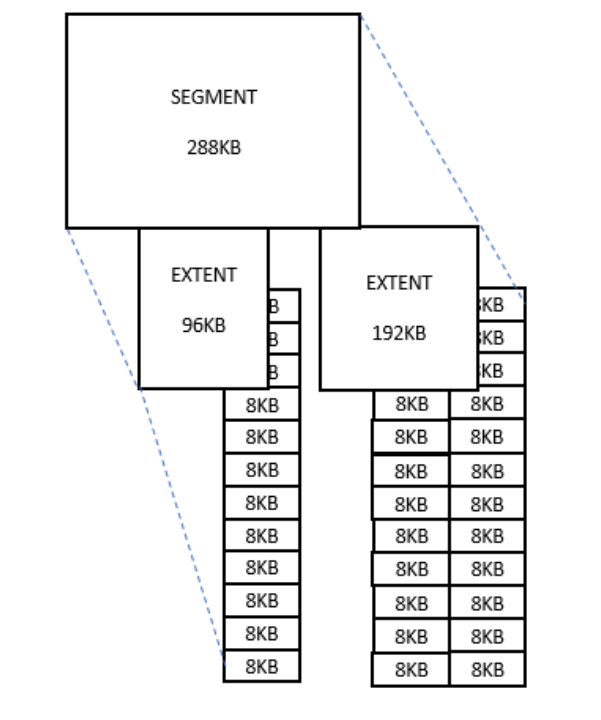
Extent是一段连续的磁盘空间,当Segment没有空闲空间时,向表空间申请一个
空闲的extent。Extent的默认大小为64K,使用大的extent可以提升全表扫描的效
率。
● page
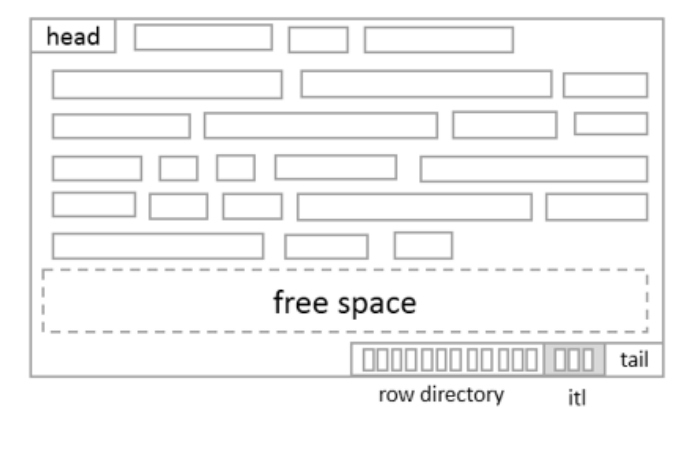
Row在page中是无序的堆放的,所以叫Heap表。
页由Page head、tail校检码、ITL列表、row dir、row组成。
– ØPage head:页面ID、Last SCN、size、ITL count、extent链表前驱和后驱节点。
– ØPage tail:CRC校检码,用于完整性校检
– ØITL:ITL列表,用于事务隔离性判断。初始默认为2个,随并发事务的增加自动扩展。
– ØRow directory:Slot偏移地址字典,可以通过slot id查找slot在页中的位置。
– ØRow:数据行,对应表中的一条数据。
– Rowid = File ID + Page ID + Slot ID,通过Rowid可以定位到一行数据。
表的分类
普通表 (Heap) | 数据全局可见,存储在普通表空 间,支持分区和lob类型 | - |
会话级全局临时表 | 数据会话级可见,存储在temp表空 间,不支持分区和lob类型 | create global temporary table t1 ( sql_id varchar(100) primary key, sql_text varchar(1000) ) on commit preserve rows |
事务级全局临时表 | 数据事务级可见,存储在temp表空 间,不支持分区和lob类型 | create global temporary table t2 ( sql_id varchar(100) primary key, sql_text varchar(1000) ) on commit delete rows |
本地临时表 | 表结构会话级可见,存储在temp表 空间,不支持分区和lob类型,表名 必须以#为前缀 | create temporary table #t3 ( sql_id varchar(100) primary key, sql_text varchar(1000) ) |
Nologging表 | 数据全局可见,存储在temp2空间, 支持分区和lob类型 | create table t4 ( sql_id varchar(100) primary key, sql_text varchar(1000) ) nologging / |
设计要点
单表(非 分区表) 的规模 | 数据量<2000万,空间 占用<10G | 表过大会导致数据非常离散,根据索引扫描 数据时物理读高,并且索引的层高也会变大 |
表/分区的 数量 | 总数量<10万 | Segment过多会产生大量的统计信息,系统 表空间会增大,同时share pool的DC占用也 会变多,bñffr pool需要保存Segment头, 内存消耗会增大 |
约束 | 唯一、非空约束由数据 库约束保证 | 如果由业务保证唯一和非空约束比较麻烦, 容易产生垃圾数据 |
列的类型 | 1.时间类型用日期类 型,不要使用字符串 2.长字符串使用clob,而 不要用varchar | 时间类型使用字符串占用的空间多,处理也 容易出错;列中包括长字符串容易出现行迁 移和行链接 |
列的个数和长度 | 个数<100,长度<200K | 列过长容易出现行迁移和行链接,并且每个 数据只能保留几条数据,索引扫描的效率会 比较低 |
Extent的 大小 | 当前还不支持动态 extent,对于大表, Extent设置为1M或8M | 默认extent是64K,对大表做全表扫描时IO 效率低,增大extent,一次IO可以扫描更多 的数据块,减少IO次数 |
数据的更新 | 避免数据更新后变长, 避免大量并发更新同一 个数据块,避免对索引 列的大量更新 | 如果把数据更新后变长,容易出现行迁移和 ITL等待,需要调大PCTFREE;并发更新同 一个数据块可能产生大量的bñffr busy wait等待;大量更新索引列也会产生大量空 块和索引倾斜,update效率也会降低 |
数据的删 除 | 大批量数据的删除使用 删除分区的方式,而不 要用delete的方式 | 如果使用delete方式删除大量数据,不仅效 率低,而且可能导致索引产生大量空块和索 引倾斜的问题 |
1.2 索引
索引的存储
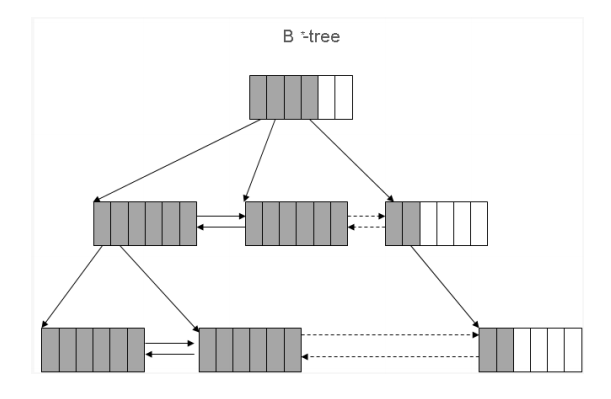
索引的数据是有序的,索引扫描(快速全索引扫描除外)只支持单块读。
● 只支持B-Tree索引,不支持Hash、位图等其他类型的索引。
● 树的顶层是根页,根页面存放下一层每个树枝节点的最小key值。
● Key的顺序为升序,页面内升序搜索使用二分查找。
● 树干节点的每个key值保存指向下层节点的指针(page id)。
● 叶子节点每个key值存放指向数据行的指针(row id),所有key都保存索引字段值。
● 扫描到叶子层后的横向扫描,是为了解决页面分裂后避免每次扫描从新从根页扫描的加速优化。
设计原则
分区表不要创建全局索引 | 分区表一般创建本地索引(使用local关键字)。如果创建了 全局索引,当删除分区时会导致索引失效 |
不要创建无用的索引 | 索引会降低DML语句的性能,所以不要创建无用的索引 |
不要创建冗余的索引 | 例如下面两个索引,如果在userid, playlistid上创建了索引, 就没有必要在userid上创建一个索引。 create index ix_ums_playcontentlist_userid on t_ums_userplaycontentlist (userid); create index ix_ums_playcontentlist_id on t_ums_userplaycontentlist (userid, playlistid); |
索引的key不宜过长 | 如果索引key过长,会导致索引树高度很大,索引查询效率会 降低。对于组合索引,索引的列不宜过多。不要把长字符串 列作为索引列,例如描述字段。 |
组合索引,要把高选 择度的列放在前面 | 如下例所示,useraccount选择度远高于accounttype,所以 应该把useraccount作为索引的首列,这样当查询条件中有 useraccount而没有accounttype时仍能高效的使用索引。 create index ix_ums_usrordlib_account_type on t_ums_userorderlib (useraccount,accounttype); |
当需要对大数据量排 序时,可以通过创建 索引来避免排序 | 场景:分页查询需要查询歌曲(总数100万),没有查询条 件,查询结果需要按照musicname排序,实际绝大部分的查 询是前几页。 解决方案:在musicname创建索引,通过索引全扫描来避免 排序,只要不是查询的数据非常靠后,效率就很高 |
一般不在选择率很低 的列上创建索引 | 一般不在状态,用户类型这种取值很少的列上创建索引。但 是,有些场景却可以创建这种索引。例如,当需要查询的那 部分的取值在数据中的比例很低时或者使用rownum限制了 每次只查询出一小批数据。总的原则是,只要一次查询的数 据在数据中的比例非常小,那么就适合使用索引。这里之所 以说“一次查询”,是因为符合条件的数据可能很多,但是 可能使用rownum限制了每次只查100条。 |
如果where语句中不 得不对查询列采用函 数查询,如upper函 数,需要建立相应函 数索引 | 如果查询条件在列上使用了函数,那么直接在列上创建的索 引是无法使用的,必须创建对应的函数索引。如下例所示。 create index ix_auditionauthlog_tonename on t_ums_auditionauthlog(upper(tonename)) tablespace ringidx; |
1.3 分区
分区表逻辑上是一个表,但物理存储是多个segment。
分区表的本地索引逻辑上是一个索引,但物理存储是多个segment。
本地索引的索引分区和表分区是一一对应的。
● 分区的好处
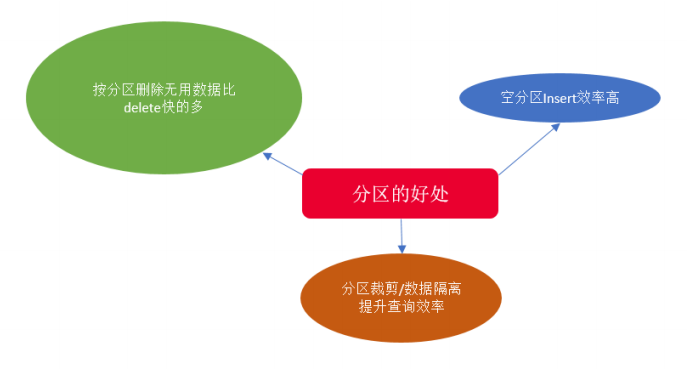
● 分区的分类和使用场景
Range | 用户创建分区,分 区键大小从小到 大,不能往中间插 入新分区,分区键 一般是date或 number类型 | 适用日志、流水类大 表,需要根据时间删 除历史数据 | CREATE TABLE WSR$_LONGSQL1 ( SNAP_ID BINARY_INTEGER NOT NULL, CTIME DATE ) PARTITION BY RANGE(SNAP_ID) (PARTITION P_0 VALUES LESS THAN (1)); |
Interval | 用户只需要设定分 区间隔和初始分区 键值,根据插入的 数据自动生成对应 的分区,分区键一 般是date或 number类型 | 同Range分区,比 Range分区使用更方 便,用户不用提前创 建分区,并且可以有 数据时再创建分区而 不用创建空分区 | CREATE TABLE WSR$_LONGSQL2 ( SNAP_ID BINARY_INTEGER NOT NULL, CTIME DATE ) PARTITION BY RANGE(SNAP_ID) INTERVAL(1) (PARTITION P_0 VALUES LESS THAN (1)); |
List | 分区键是离散值, 分区需要用户创建 | 适用在分区键是离散 值的场景 | CREATE TABLE WSR$_LONGSQL3 ( SNAP_ID BINARY_INTEGER NOT NULL, CTIME DATE ) PARTITION BY LIST (SNAP_ID) (PARTITION P_0 VALUES (1)); |
Hash | 用户设定分区键和 分区数,可以自动 生成分区,插入数 据时根据hash算法 选择对应的分区 | 适用于分区键取值非 常多的场景,一般用 于把数据隔离开,而 不是为了根据分区删 除数据,使用hash分 区减少bñffr busy wait的等待 | CREATE TABLE WSR$_LONGSQL4 ( SNAP_ID BINARY_INTEGER NOT NULL, CTIME DATE ) PARTITION BY HASH (SNAP_ID) PARTITIONS 16; |
● 分区的注意事项
查询分区表 | 一般要带分区键查询,并且分区键的查询条件上没有表达 式,如果扫描所有分区可能性能不如不分区 |
分区表的开销 | 分区表过多segment和统计信息会增加,内存和磁盘开销 会增大,分区不是越多越好 |
创建索引 | 分区索引原则上要创建为local索引,避免删除分区时索引 失效;如果分区内分区键是同一个值,不要在分区键上创 建索引 |
● 分区的设计要点
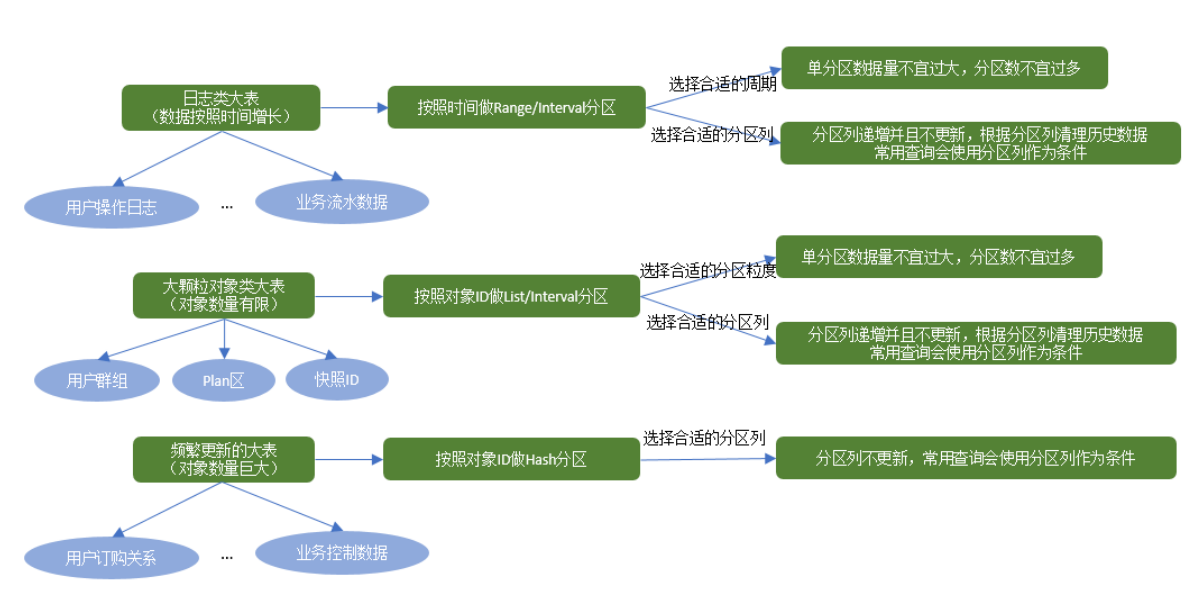
2 分布式
2.1 分库方案
各种分库方法没有优劣之分,只有更适合具体的业务场景
哈希 | 分布列值用Hash函数计算,落在 同一个Hash桶的值分布到相同的 数据节点。 | 分布列的取值在1千以上,要求数值的均 匀分布,防止数据偏斜。 |
范围 | 分布列划分不同的范围,同一个 范围的数据分布到相同的数据节 点。 | 分布列的取值是连续的。 |
列表 | 按照列的取值和数据节点通过枚 举的方式建立对应关系。 | 分布列的取值是有限个数。 |
复制 | 表在所有节点复制一份。 | 该分布方式为其他分布方式的辅助,针对 容量小的变更频率低的维度表采用复制表 的方式。 |
2.2 分布式 SQL
分布式中,根据路由规则,分布式SQL语句的执行计划主要有两个策略:
● 下推整个SQL语句到DN执行:指直接将整个SQL语句从CN发送到DN进行执行,然后将执行结果返回给CN。
● 下推部分SQL语句到DN执行:指在无法将整个CN下推到DN执行时,CN将SQL语句拆解成多个部分,将可下推的查询部分组成查询语句(多为基表扫描语句)下推到DN进行执行,获取中间结果到CN,然后在CN执行剩下的部分。
从上面的两个策略可以看出,策略1会将整个SQL语句直接下推到DN进行执行,该策略是比较友好的执行方式,效率高;而策略2要将大量中间结果从DN发送给CN,并且要在CN上允许不能下推的部分语句,会导致CN成为性能瓶颈(带宽、存储、计算等),在进行数据库设计与性能调优的时候,应尽量避免出现选择策略2的语句。
执行语句不能下推是因为语句使用的路由规则不合适导致的,例如下面列出了几种可以实现直接下推整个SQL语句的场景,具体如下:
● WHERE条件中包含分片字段,可以直接下推到具体某一个DN执行,例如:
create table t1(s_id int not null, s_name varchar(100) not null) distribute by hash(s_id);
select * from t1 where s_id = 1;
● JOIN:表关联时,关联条件中需要包含分片字段,例如:
create table t1(s_id int not null, s_name varchar(100) not null) distribute by hash(s_id);
create table t2(c_id int not null, s_id int not null, c_score double not null) distribute by hash(s_id);
select a.s_name,b.c_score from t1 a join t2 b on a.s_id=b.s_id;
● GROUP BY:在分组查询时,分组字段中需要包含分片字段,例如:
create table t2(c_id int not null, s_id int not null, c_score double not null) distribute by hash(s_id);
select s_id,avg(c_score) from t2 group by s_id;
● ORDER BY:在排序查询时,排序字段中需要包含分片字段,例如:
create table t2(c_id int not null, s_id int not null, c_score double not null) distribute by hash(s_id);
select * from t2 order by s_id;
相关阅读:
1. GaussDB T 性能调优——硬件环境
https://www.modb.pro/db/22263
2. GaussDB T 性能调优——SQL问题分析之常见问题和案例分析
https://www.modb.pro/db/22261
3. GaussDB T 性能调优——SQL问题分析之CBO trace 日志
https://www.modb.pro/db/22258