金声玉振-数据库技术和生态变革创新的十年
墨墨导读:2020数据技术嘉年华于11月21日落下帷幕,大会历时两天,来自全国各地的数据领域学术精英、领袖人物、技术专家、从业者和技术爱好者相聚北京,见证了个人的快速成长、技术的迭代进步、行业的蓬勃发展、生态的融合共赢,以及市场的风云变迁。
本文根据盖国强老师在2020数据技术嘉年华演讲速记以及PPT整理而成。
(全文第一人称描述,代指盖老师)
以下为正文:

2020数据技术嘉年华 盖国强先生现场演讲
数据库的发展,我仍然是看成三个时代:从Oracle代表的商业数据库时代,MySQL代表的开源时代,以及云数据库时代,或者新数据库时代。在云数据库时代中,真正有一大批国产数据库成长起来了,走上了历史的舞台。
国产数据库中,OceanBase是从2010年开始的(今年是他们的十周年);2012年的TDSQL;2014年的GoldenDB;2015年的TiDB;2017年的PolarDB;以及2019年的GaussDB,并且GaussDB在今年6月份,开源了openGauss这个品牌。所以整个数据库进展到一个新的时代,这个新的时代不仅仅是云,还有国产各种形态百花齐放。

我把以上六位嘉宾的产品各自选择了一个案例,给大家推荐一下。
我们知道阿里云的PolarDB已经支持了国计民生很多领域,去年支持了中国邮政,双11也取得了非常好的成绩;GaussDB 在工商银行的金融场景中替代了国外的产品;北京银行使用了TiDB;OceanBase 在上海外滩大会发布了西安银行的互联网交易替换;GoldenDB在中信银行,从去年的信用卡核心到今年的交易核心上线;TDSQL最新的案例则是昆山银行。
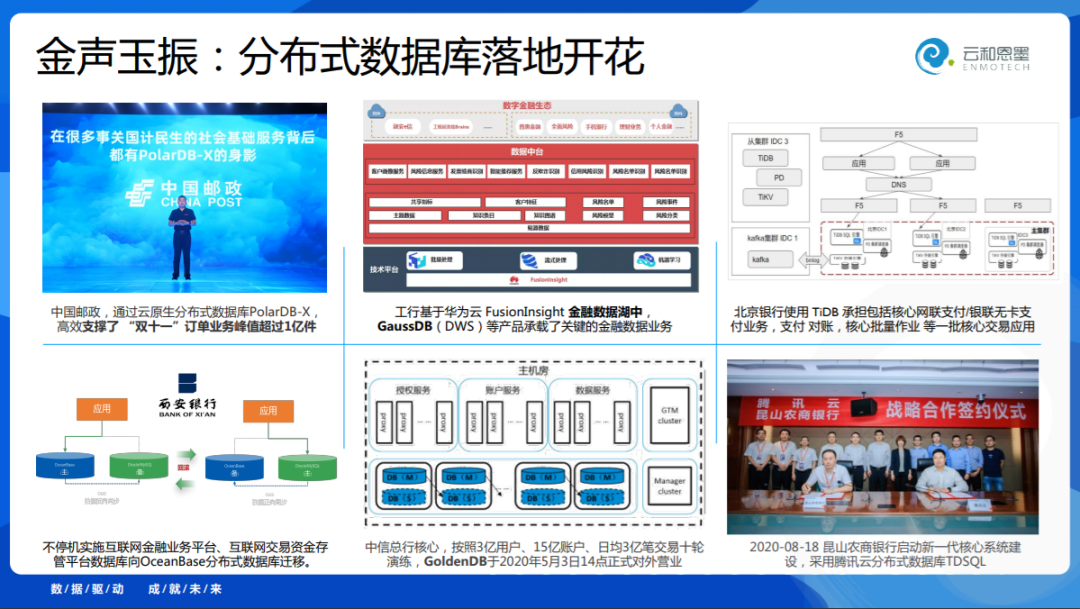
我们看到这些数据库产品都在非常重要的生产实践中得到应用,而且几乎都是分布式数据库,不经意间,分布式数据库已经走上了历史舞台,并且落地开花了。那么分布式数据库是什么时候流行起来的,并且可能成为未来的演进趋势呢?
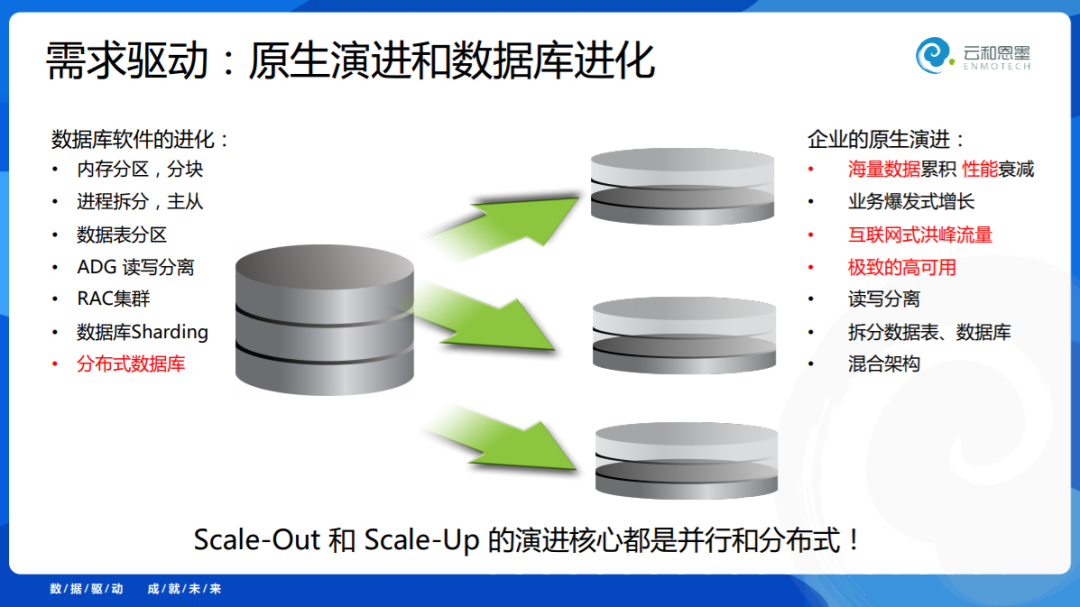
分布式数据库来源于用户需求的驱动,用户的需求是什么呢?是海量高并发的应用场景、是互联网式的应用创新,在这样的业务驱动之下,用户的原生自主演进就是读写分离、分库分表。有了用户的业务驱动创新,最后数据库厂商把这些特性做进了数据库产品里面去,到数据库内部其实是什么呢?是分区、分片、分块,进程的拆分。数据库内部的分区分表,最后演进到了分布式。
不管我们谈的是Scale-Out还是Scale-Up,本质上都是希望通过各种技术提高性能和承载能力,这些本质上的技术是什么?不外乎是并行和分布式。技术的进步来自于用户的需求驱动。

在很长一段时间内,分布式和集中式是存在争议的,这是一个路线之争。分布式技术在什么时间取得了突破式进展呢?谷歌的三驾马车在这起到了奠基作用,Google 的 File System、Google MapReduce、Google BigTable,这几篇论文奠定了分布式数据库的基础,分布式技术在这之后得到了很好的发展。为什么在这个演进过程中几乎没有人提到 Oracle?
我在这里引用了一篇文章,2008年Oracle有一篇非常好的文章,他说Global Scale Web 2.0,这是一个非常久远的历史了,Web 2.0 大家可能都不记得了。这篇文章描述了,在分布式架构下应用的设计和局限,这里引用了其中一些关键的观点。
-
Sharding,它是联合使用众多独立数据库的应用管理扩展技术,本身是应用管的,在应用上要做出很多的适配,数据要切分成多个数据库,每个数据库存储一个数据子级,是这样来实现的。
-
要实现这样的架构(使用分片),应用程序要为此做出让步,做出大量的修改,要基于Shard 去做应用的设计,要尽量避免跨库的join。为了实现本地化的连接,可能要反范式去设计你的数据模型。所以你面对的是这样的一些挑战。
-
分片式架构的一个变体实现是,在分布式里面每个数据库都承载了全量数据,其中有一个数据库承载了写请求,其他是承载读,这样我将读写分开。它的好处是每个库承载全量数据,复杂查询就在本地完成了,还不需要进行re-Shard。阳老师所讲的OceanBase就是类似于这样架构的变体实现。每个库都是一个全量库,当然它的每个数据库又可以进行分区分布。
这几个观点来自于Oracle的这篇文章,当然它是作为反面示例来陈述的,它们都有缺陷。在那之后,一直到了2017年Oracle才推出了Sharding数据库组件,也就是分布式的数据库,整整过去了十年。

Oracle数据库历程是怎样走过来的?它如何走过了从单机、主备、集群到分布式?
Oracle走过的这条路很难被超越,我们要学习和借鉴、研究它,这条路仍然不会变。
从8i这个时代,1998年Oracle这时候的版本叫Internet,它理解互联网的历史非常久远。这个时代我认为有非常重要的一件事情,今天对于所有的国产数据库厂商要借鉴的,这个时候就做了在线支持系统 - Metalink,很多同学知道它意味着什么,能够及时的获取你想知道的知识,解决问题的提示,已知的bug,提交的问题,每个厂商都应该建立的一个系统。
到了2001年,9i那个年代,Oracle做了 Linux 发行版;还有7版开始、8版改进的OPS,到了9的时候真正成熟了叫Oracle RAC,然后开始做什么呢?把 Automatic - 自动化技术放到数据库里面,我们今天很多国产数据库提到的AI,很大程度上是自动化的,Oracle在这个方面做了大量的迭代。
到了10g的时候做了ASM存储管理软件。到了11g的时候做了ADG,当年的淘宝在第一个阶段就使用了。
然后Oracle在2012年开始跟进了Cloud,这也是Oracle唯一的一次错判市场,亚马逊在2006年推出S3的时候,Oracle 认为这不是未来,到2012年才开始跟随,至今仍然在追赶。
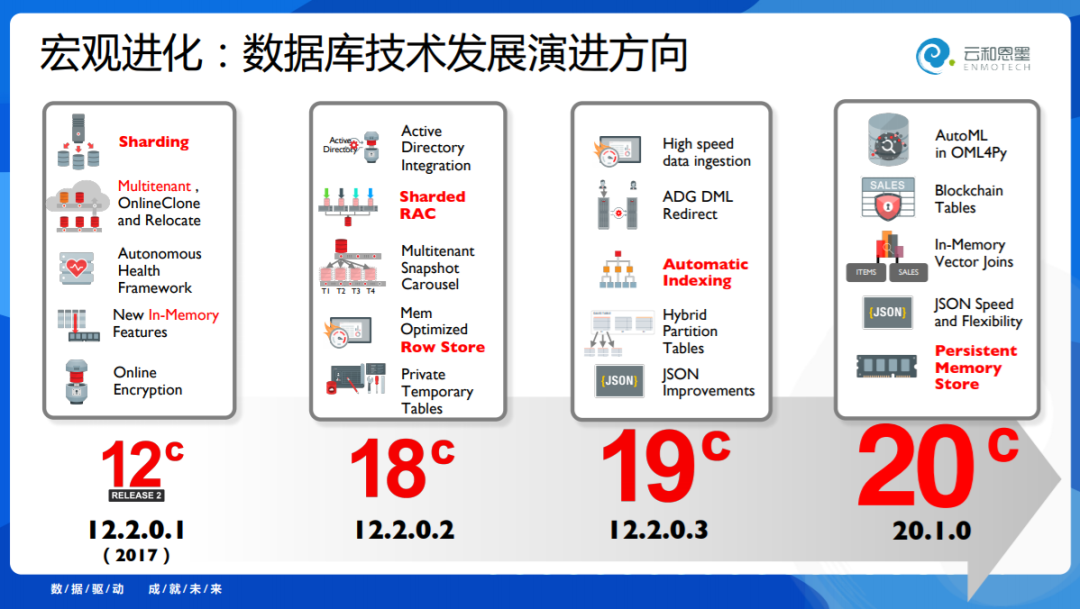
再往前演进,进入了云数据时代 - 12c (C 代表 Cloud),2017年的时候推出了Sharding,这是分布式技术进入了Oracle。然后到了2018年18c,做了Sharded RAC,这是将分布式技术局部引入了集群中。
到19c做了自动化索引技术,我们认为它是具备AI属性的技术。到了今年20c,它引入了区块链、AutoML等。
Oracle 公司有一个非常强大的能力,它会快速的能够把那些非常具有实践价值、领先价值的技术,嵌入到数据库内部去。在外部的时候很难应用,比如说machine learning - 它的门槛特别高,但是Oracle把它放在数据库中,应用门槛就降低了,包括区块链技术,这是特别值得学习的。
我跟大家稍微分享了一下Oracle 在宏观上的演进,它今天真的把AI的技术放到数据库内部了,但是更重要的几点是什么呢?包括持久性内存 - 这里面其实就看出了数据库技术演进的方向了 - 包括软硬结合,包括多模,分布式等等。其实这也是前面几位嘉宾讲到的,我们看到数据库发展的方向,是确立的,大家的认知是相同的。
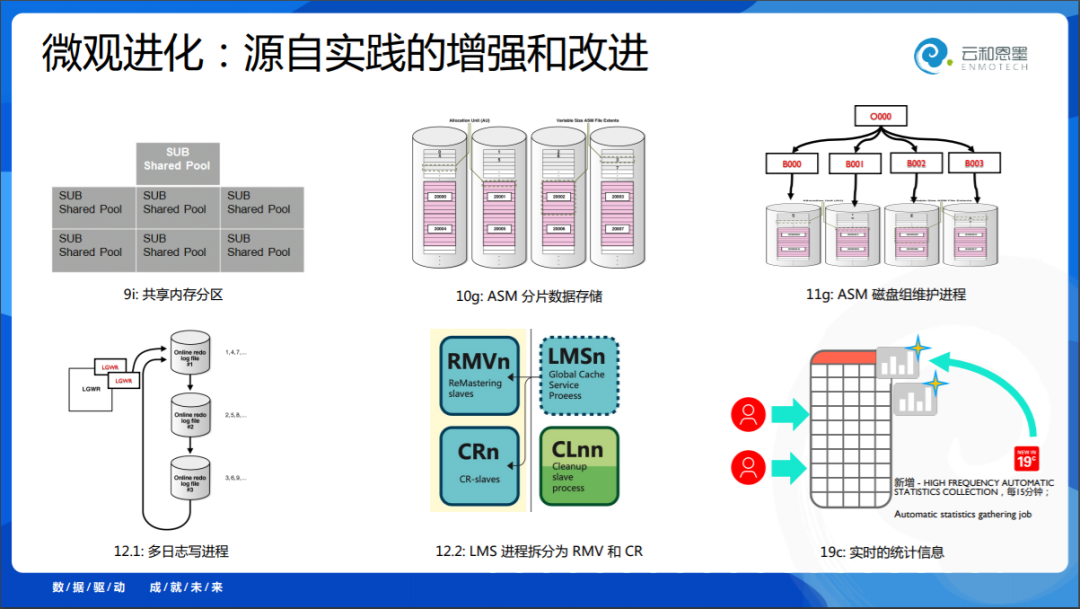
除了宏观上的演进,微观上的演进来自于实践。当用户应用中遇到问题的时候,反馈出来并做了修正。我举了六个小的案例。
1. Oracle在9i的时候把共享内存做了分片,以前是一个共享内存段,存在高竞争的问题,闩锁竞争会很激烈,9i 进行分区细化,缺省可以有7个子池,并发性就更好了。
2. Oracle在10g的时候做了ASM自动存储技术,其实就是一个分布式存储。
3. 到了11g,Oracle把每个磁盘组设立独立的进程维护、守护。O000调度B001、B002...子进程。以前是用一个进程的,可是当你有一百个、一千个磁盘组的时候,它的维护就变得非常复杂漫长,你要经历很长时间的等待,现在进程拆分通过并行解决了这一问题。
4. 到了12.1,它多日志写进程变成并行处理,这是Oracle数据库内部最重要的,最后的并发瓶颈点了。
5. 到了12.2 LMS和很多进程几乎都拆分了,包括RM、CR进程,所以你在Oracle数据库里,有时候能看到数据库自身的后台进程,很多都是成百运行起来的。
6. 19c的统计信息,偏静态和偏动态的,隔离处理、并行处理、实时处理。
很多特别高大上的理念在数据库里边要真正落地才算数。Oracle在19c开始引入AI自动化索引技术,我认为是非常重要的,我也期待国产数据库里也能快速实现它,它能根据应用的SQL自动的分析,应该创造什么样的索引对查询有帮助。它是一个模拟的专家系统,就跟我们人的思考是一模一样的,Oracle把它实现出来了。
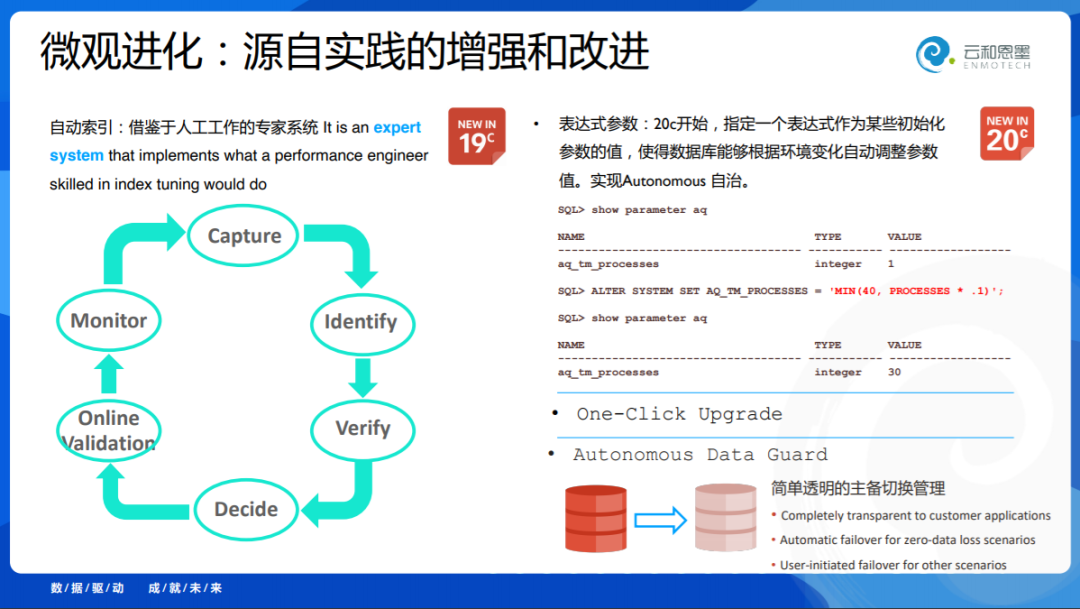
然后我们再来看这一侧,Oracle原本因为今年要发布20c,但是因为疫情没有全面公众发布,但是再过两个月它要发布21c了,迭代进步是非常快的。
20c里面有几个非常小的细节:
-
引入了表达式的参数 - 我们经常遇到这样的情况,一个DBA装完数据库了,没有去看硬件配置,用初始化配置就去跑了,或者用经验配置往往不是优化的,现在把大量的参数变成了表达式参数,你可以为他设置一个表达式,可以自动的根据你的系统配置进行调节,更加自治。
-
Oracle实现了一键式自动升级,这从18c开始实践,20c更进一步了;
-
Autonomous Data Guard:主备自治切换,当你发生故障时,判定零数据损失情形下,数据库就自动切过去了,不需要你干预。
这些细节上的变化,我个人认为特别值得我们学习和关注,在我们国产化的数据库里实现,去把它做出来。
刚才通过一个小结的分享,我跟大家分享了一下为什么数据库技术走到了分布式这样一个时代,并且我也认为Oracle后续的演进是值得我们去借鉴和学习的。
我还想试图回答另外一个问题,今天用户进行选择的时候是非常困难的,有太多的数据库品种了,我们怎么样去选择?有Oracle,MySQL,还有各种开源和国产化数据库。
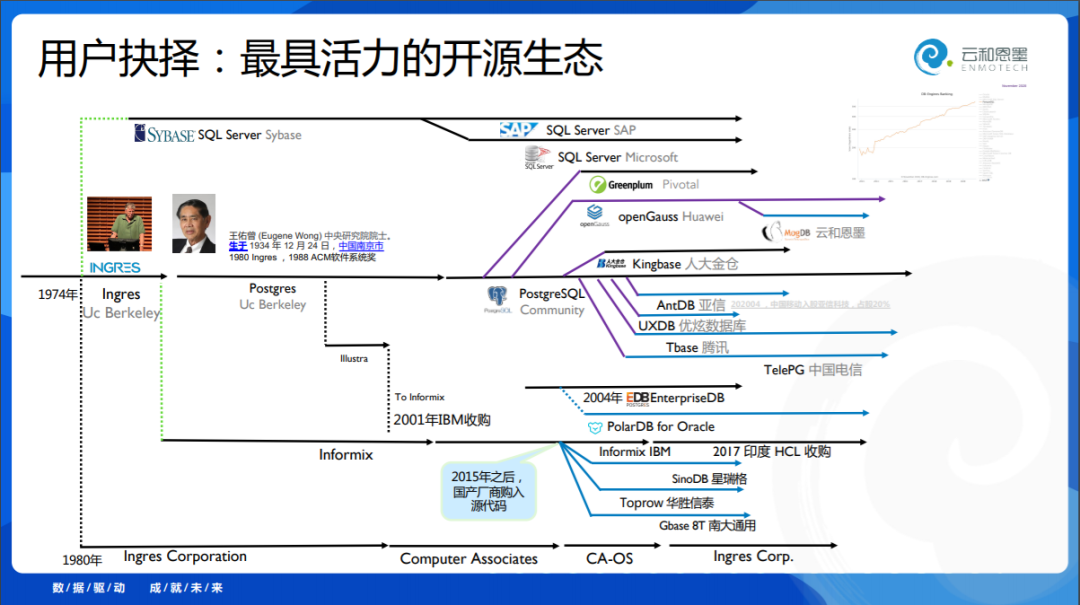
我个人的观点是去选择那些最具活力的生态,什么样的生态是最具活力的?我最近在关注PG,我发现这个生态既有渊源的历史,又有广阔的现在和未来。有人说MySQL的生态非常好,但是我个人感觉中国PG生态的内核开发者应该是最多的,因为在PG路线上有大量国产化的分支存在。我们知道中国电信在做TelePG ,腾讯有TBase,优炫 UXDB,人大金仓 Kingbase,以及华为开源了openGauss,云和恩墨也在openGauss的基础上发布了MogDB,在这个生态上存在的数据库是非常多的。
再倒退一步,我观察PG历史的时候,我发现技术应该是没有国界的,很多人说开源就是国外的,是拿来主义,但是我发现在源头 Michael Stonebraker 教授创立Ingres这个产品的时候,就有中国人的身影,他是王佑曾博士,他和 Michael 在1980年联合创立Ingres,并且他本人也获得1988年ACM软件系统奖。所以我认为公司有国界,代码无国界。
很多人应该非常清楚,Ingres发展出来的技术生态在全球是最丰富的、最源远流长的,它曾经诞生了Sybase、Informix这些时代产品,今天还有 PostgreSQL 这么丰富的生态体系,我非常看好它。

回应一下我刚才提到的,今年我们接触到的、我本人也在学习的openGauss数据库,它本身是基于PG 9.2做的分支。华为在此之上进行了大量内核的研发,并且在今年6月30日的时候把它开源了。它做了什么样的显著改进是非常值得大家关注的,我先说几个非常时髦的关键词汇,在上面大家看到有AI自调优,有ABO的优化器,有In-DB ML ,这些都是今天数据库领域最重要的热点方向,大家可以在这些方向投入关注。
阿里云的云数据库上,有一个iBTune,就是自动来调参数的。基于在线的调整,为数据库节省了20TB的内存。这个方面的研究是非常有价值的,openGauss也在做,并且实现了参数自调优。ABO优化器想做的是基于AI的自主优化,再加上Machine Learning,这是Oracle在做的,这非常重要,就是把特别有门槛的事情带到数据库内部。
回到现实来看,openGauss做了几件事情值得大家去学习。第一个它把PG改成了线程模式,从此可以支持上万个并发;第二个它支持了事务CSN快照、增量检查点。还有它同时开源了行存、列存和内存引擎,这是原来基于企业级的需求,迭代到了开源数据库。
我回答了上一个问题,如果企业选择应该怎么选,当然应该选择最活跃的生态,刚才几位老师也讲整个生态非常重要。

再往下我想给DBA们再讲一讲,当我们过去学的是Oracle或者另外一个数据库,今天想切换到国产数据库或者开源数据库上,怎么快速的进门和提升。我的方法是由浅入深,我认为最好的能力是获得一种可迁移的学习能力,你就不在乎我到底学的是A还是B。我个人的方法是由浅入深,从你遇到的问题出发向下追溯,找到根源,我在Oracle的学习中就是这样的,当你遇到和溯源了很多的问题,你的钻研就会形成一个知识体系。
我举一个案例,这是今年我们遇到的客户案例,对于初学者这是一个合适的挑战了。
从错误提示:这个数据库的事务号只剩下一百万了,必须要进行回收,数据库陷入冻结。也就是说这个数据库不能接收任何事务了。客户在回收的时候发现失败了,出现什么问题呢?
两个错误:不能够 open relation,automatic vacuum 失败。如果是用我们过去的能力方法,在Oracle的世界里,我们是不断地去下溯,但是今天我们面对的是开源数据库,可以直接看源码,这简直太让人兴奋了。
两步走,我的土办法跟大家商榷,首先看这个错误是从哪抛出来的,因为是automatic vacuum 出错,所以我首先拿出 pg 的 autovacuum.c 源码,很快就找到了抛出异常的代码(上图左一)部分。因为什么出现异常呢?是在做table open的时候,本质上是vacuum 要去轮询对象。继续追溯 table open,找到 table.c 源码,可以看到 table open 调用了 relation open,根据 ID 号去打开对象。继续下溯 relation open 是怎么写的,在另外一段源码里 - relation.c,这段代码做了什么?它根据你提供的ID打开磁盘对象,如果失败了,所以就出现错误。现在从这个错误倒回来看,那就是整个的异常处理流程。最先抛出的是不能open relation,然后是 automatic vacuum 失败了。
通过这样一个简单的分析,我大约就能把这件事情理解的比较清楚了,我们再花一点时间把这三个源码文件仔细读一读,就能对PG理解的更进一步。是不是很有意思?我个人觉得很有意思,就这样你在开源的世界里要找到乐趣,然后你的研究就能够深入。

我们再往下看,这个事情是怎么存在的?就像Oracle数据库里面,大家知道可能SCN越界跑满就挂掉了,后来Oracle把6 Bytes的SCN改成了8 字节,我以为在PG里没有这回事,PG内部使用儒略历,可以记录从公元前4713年到未来无限长的时间,但是没想到事务号上存在一个瓶颈,事务号是用的32位来存储的,所以当它的事务号用尽的时候就发生回卷,在PG世界里是非常头疼的一件事,到了openGauss里面非常好,他把事务号变成了64位的,就把这个事情解决了。
我们可以做一个测试,在 openGauss 把事务号提升到20亿以上,范例把事务号提升到了45亿,证明了它的上限,是不受限制的。怎么测试的呢?你在PG里面做也好,就用到我们刚才遇到的问题案例,你可以创建一个表把它干掉,阻止数据库自动Vacuum,然后就去拉升事务就好了,用不了多久就重现了。
所以你看我们就是在这样的探索过程中找到乐趣,然后通过这些乐趣,通过这些问题你自己得到学习成长。所以我个人认为获得这样一种可迁移的技术能力是最重要的。

讲了一段技术,正因为比较看好PG在中国的生态发展,又加上openGauss的开源,今年云和恩墨和华为进行了合作,推出基于openGauss 的 MogDB,这个Logo看起来就是一只猫,它的本意是EnMotech openGauss Database Enterprise Edition,我们希望它能打造成一个最易用的 openGauss商业版。
一个数据库不仅仅是有了内核就能用,它还要有周边所有的一切,比如自动化的运维、运行监控、高可用HA,所以我们率先发布了一个HA版本,就是帮助用户实现自治的高可用。我们也发布了 OpenGauss Docker版本,现在大概有近2000次的下载量。9月份的上海华为HC大会上,我们还和民生银行一起获得了 openGauss 超级用户大奖。
总之,这是云和恩墨在开源方面的尝试,也希望通过这样的尝试给用户多一个选择。
多一个选择是好还是不好呢?这取决于看问题的角度。

用户今天面临了太多太多的数据库了,我本人也认为百花齐放的中国数据库生态,十年可期,它是一个持久战,不是今天大家就能看清楚,不是我们讲大家就能信,很可能你不信,将信将疑,或者根本不信,可能需要一个漫长的时期才能看出来哪些产品会生存下来,站住脚,所以我认为数据库的国产化之路是一个长期的过程。
在这个过程中用户肯定是迷茫的,我如何去选择,又因为人才的培养周期同样是非常漫长的,所以我们的理念是,今天用户去选择一个新的系统,应该先建能力后建系统,也就是说我先把整个数据库服务平台建起来、自动化服务能力建起来,借着这样变革的机会,把企业数据库管理、运维管理变成自治、智能 - 这是一个变革之机,我们的思想一直是这样的,云和恩墨是数据库领域生态参与者,我们将自己的 dbPaaS 平台 zCloud,打造成了一个多数据库管理纳管,自动化、智能运维的一体化平台。就是希望帮助用户在变革的长周期内简化你的工作,能靠软件系统完成的就靠软件系统。
我们整个平台把它拆解开,又分成了一系列的小的产品,当然底层有一体机zData、备份一体机ZDBM,向上有监控Bethune 、还有质量管控平台SQM。这就是云和恩墨今天在做的事情,我们对行业的看法,我们产品从2015年开始探索,包括像华泰证券、东航都是我们的重要客户,深度应用的客户。

最后我想讲讲我个人对行业的看法,我在2019年写过一篇文章,我把2019年称为中国数据库的元年,为什么?我认为天时地利人和在去年就具备了。中国的数据库厂商众多,在墨天轮的排行榜(modb.pro/dbrank)有105家现在在榜上,还有100家没有上来。我把这些厂商分成了四个流派:
第一是学院派,他们多数是从高校和科研院所出发的,是非常早期的探索者,这里边有人大金仓、武汉达梦、南大通用、神舟通用等。
第二是互联网派,他们首先经历了自身应用的考验,所以说PolarDB、OceanBase、TDSQL、TBase,在互联网经历了大规模生产压力之后,到企业里来能不能用?一定可以用,找到适合的场景就可以用。
第三是蓬勃发展的创业派,今天PingCAP做到2.7亿美金的融资,大量国内的数据库创业厂商。这里边有巨杉、PingCAP、偶数、星环、柏睿、星瑞格、易鲸捷,多数今天都来到大会现场了,也都有分享。
第四是科技企业派,中国的科技企业巨头来到市场上了。华为、浪潮、中兴都来了,他们过去在To-B领域深耕,最懂企业级用户的需求,也有资金和科研力量的支持。
我认为这四个分支和派系,在未来都会有卓越的产品冲出阵营,走进用户的生产实践。
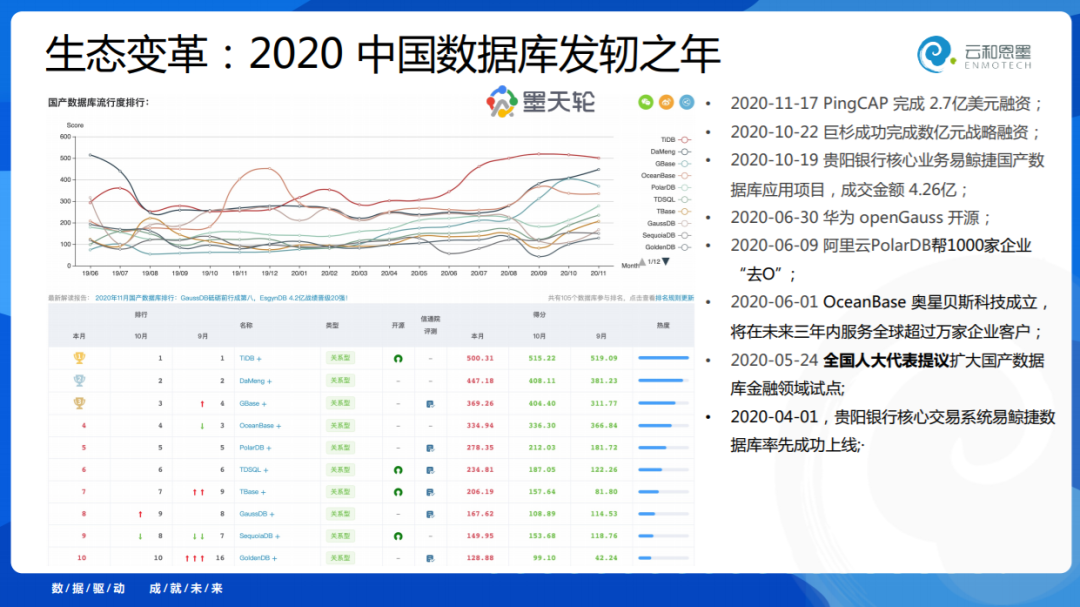
2020年我认为是发轫之年,所以有特别特别多的好消息出来,11月17号PingCAP完成融资,巨杉也完成了几个亿的融资,10月份贵阳银行在易鲸捷有一个4.26亿的整体项目,是创记录的。630是华为的openGauss开源。6月9号PolarDB打出了帮了一千家企业“去O”的口号。6月1日,奥星贝斯成立。这是中国数据库最好的时代。墨天轮打造了国产数据库排行榜,刚才东旭帮我展示了一下,我们希望在生态里为国产数据库发声,做一些事情。

躬身入局,最近好多DBA给我打电话说他很迷茫,说Oracle还能不能搞,国产我应该学谁,他们是迷茫的。DBA还行不行?我讲两个观点。DBA一定行,因为数据对于企业是最重要的,DBA是驱动数据库成功应用、稳定运行和持久演进的驱动力量,你说行不行?一定行。
第二,DBA是有精神的,责任心、服务心、沟通心、进取心和分享心,这是周彦伟在文章当中写到的,DBA不要迷茫。
我说数据库的最后一公里,得DBA者得未来,所有的厂商都在做学院培训,没有人怎么做生态?怎么做服务?怎么帮用户?所以得DBA者得未来。
-
这是一个新的时代,一主一备双引擎,商用开源两相宜。不能守住一个山头了,商业和开源、国产都是你的目标,要把你的技能进行迁移。
-
躬身入局,引用了一张得到的图,什么叫躬身入局?不要迷茫,不要站在岸上迷茫,要迷茫跳下去迷茫,要到浪潮里去游,只要淹不死你就成功了。我说从短期内我们总是高估了难度,我们总是觉得这是一个新的事物很难。东旭刚才讲,那么多技术学完了就三五万,全会了就十几万月薪。但是从长期看我们低估了机遇,你把这些都会了你的身价就提高了,你干吗不进去游,站在岸上干嘛,所以我说一定要拒绝迷茫,躬身入局。躬身入局的好处就是先入为主,谁先进来了谁当家作主。我们都知道PG是德哥的场子,我进来晚了。我努力,躬身入局。
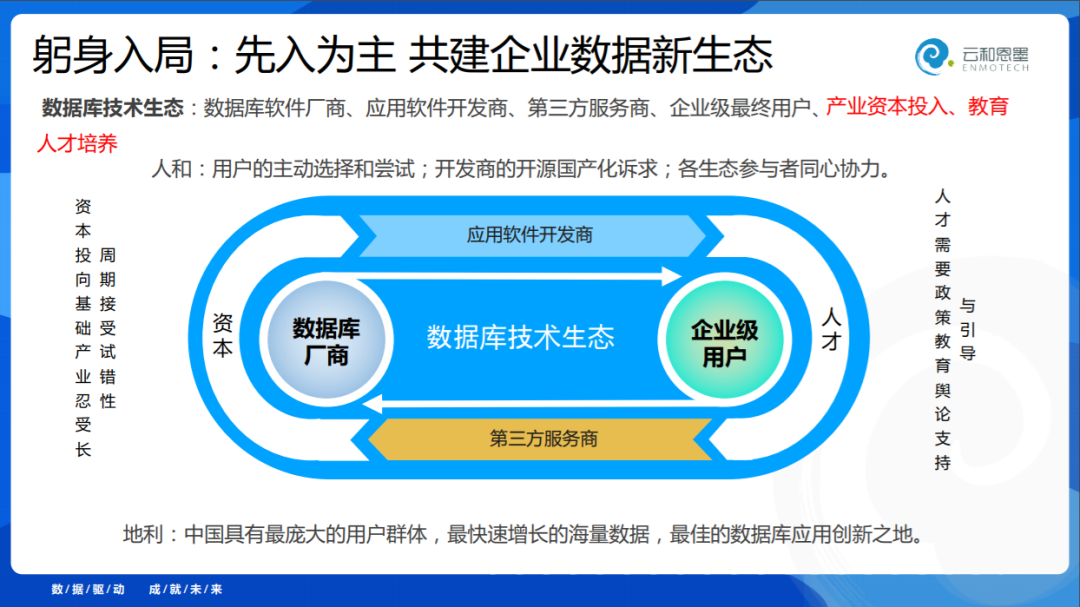
数据库的发展需要全流程的,从厂商到企业用户,全流程的都要运转起来,单靠任何一家都不行,我为什么说2019年是数据库元年呢?以前是数据库厂商自己使力气,非常吃力。如果有了开发商和第三方厂商,最重要的是要有资本和人才涌到这个行业里,这个事情才成功了,要引起所有人的关注,这个行业才成功了。
我昨天发的一篇文章有人留言,国产数据库开始进入炒作时期,我说这对了,以前你在低谷里喊一声没人听见,怎么能发展呢?当越来越多的人议论它,我们数据库才能得到发展。今天是天时地利人和的最好时机。

最后总结四句话,也是我今天想回答的四个问题。
1. 云和分布式,确立了未来发展的两大重大方向,非常重要,所以要学习分布式技术。
2. 他山之石以攻玉,数据库技术发展这么多年有了特别特别多值得我们学习和借鉴的,尤其是在国产数据库进行研发变革的时代,要脚踏实地扎扎实实做好技术。比如阳老师说了最好能拿到TPCC上溜一溜,这有很多挑战。
3. 躬身入局,与其原地迷茫,不如先入为主,谁先进来谁得天下。
4. 天时地利人和,这是数据库最好的时代,也是我们所有人的最好时代。
想都是问题,做就有答案。我希望中国的数据库产业发展的越来越好,也希望大家都能够躬身入局,找到更好的未来,特别感谢大家来到今天的会议现场,谢谢大家!