<< 返回文章列表
指标是数据库运维中十分关键的元素,不仅仅是监控告警,巡检、故障溯源、问题分析、性能优化等也都依赖于各种各样的指标,因此构建指标体系是数据库自动化运维的基础。
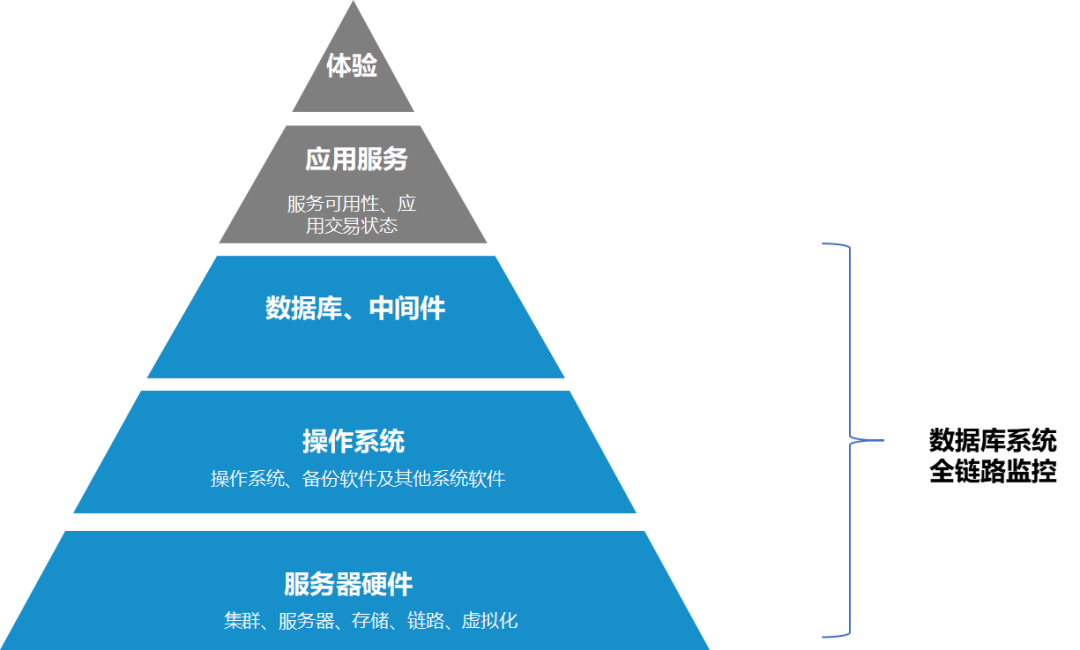
一些运维系统中,设计理念重算法,轻指标,认为无论用户采集的系统运行数据的质量高低、数量多寡,他们都能很好的帮助用户构建智能化分析与预警的平台。然而,这类运维系统在实际生产环境中的表现比POC 差很多。因为 POC 的数据往往都是用户系统出现问题时的重现数据,故障特征比较明显,所以哪怕数据质量不太高,也能有比较好的效果,而同样的算法,在故障特征没有那么明显的生产环境中,效果就不尽如人意了。从这类系统的表现可以看出,构建全链路数据指标对智能运维是十分必要的。这里所说的全链路指标构建是从数据库系统的角度,把影响数据库的关键指标都采集监控起来,不是仅采集数据库本身的指标。
再进一步,全链路数据指标固然对诊断分析有很大的帮助,但并不是指标采集的多就够了,除了指标的覆盖面,指标的专业度和准确性才是关键能力所在。企业所使用的数据库、中间件、存储、网络设备等指标有大几千个,如果指标设计的太冗余,不仅采集意义不大,还会影响采集性能。再加上频繁的周期采集,一旦导致积压的采集任务过多,会把数据库彻底压垮。所以高效、低开销、高密度的采集全链路数据库指标才是实现数据库运维自动化与智能化的基础,更是运维经验和能力的体现。
如何平衡指标既全面又准确呢?zCloud 在设计中融入了三点设计思想:
一是将运维经验融入到指标采集模型中,从指标源头保证,这非常考验运维软件设计团队的专业能力,需要掌握足够多的能够影响系统的关键数据。
二是采集时尽可能用最简单的 SQL 和方法,不在源端做统计分析,把这些工作都放到运维平台,这样可以最大限度地减少指标采集的开销与风险。同时,尽量使用一些风险较小的指标来替代高风险的指标。
三是运维软件要拥有全链路分析的能力,构建全链路的监控视图,把相关的运维对象之间的关联关系构建出来,利用运维专家的知识定义出大量的全链路影响的模型。
下面我们通过一个真实案例来看看 zCloud 数据库云管平台的智能诊断模块,是如何通过对全链路数据监控数据分析对异常进行诊断的。
很明显, 引起业务响应慢的主要原因就是数据库会话阻塞,继续对阻塞问题进行下钻分析,点击诊断详情查看诊断分析树(如下图),很快发现了一条诊断路径:“堵塞会话多--》 GC 延时高 ---》 SQL 语句 GC 请求块重试、丢失数量多----》 Linux 主机网络失败次数过多,Netstat 专业指标异常”。通过zCloud 智能诊断模块内置的专家定义问题和诊断路径,可以快速的对全链路的监控数据进行排查,下图清晰的展示了部分检查逻辑和排查点。可以看到 zCloud 在诊断树的其他节点,是排除了集群心跳问题、LGWR 进场问题,以及数据库 IO 延时等问题之后,最后指向了:“Linux 主机网络失败次数过多,Netstat 专业指标异常”的根因。
最后根据诊断树显示的根因,点击“Linux 主机网络失败次数过多”查看问题详细描述,看到几个库的网络超时严重(如下图),DBA 快速的 GET 到这很可能是一个包重组引发的心跳性能差问题。
此时,距运维人员报告业务响应慢的问题仅过去5分钟,DBA 就利用 zCloud 的智能诊断模块快速定位了引发业务响应慢的会话阻塞问题。
问题的根因找到了,还需要对症下药——可以通过设置更大的缓冲区来解决,具体操作如下:
如果在 zCloud 中提前设置了缓冲区相应的参数,这类问题可以在智能诊断页面自动给出解决方案,经 DBA 确认,点击几次鼠标即可完成故障恢复,更加便捷。整个事件从发现业务问题到恢复正常,在 zCloud 的帮助下花费不到10分钟。
复盘这个案例,zCloud 智能诊断通过分析比对故障模型,基于全链路的监控数据进行关联分析,逐步缩小诊断范围。在对集群、主机、操作系统等相关指标判断后,最终定位到网络的问题。而如果人工查找问题根因,DBA 需要进行一系列数据 “人工关联分析”:
首先:这类网络问题,一般情况下 DBA 都不会直接关注,直到数据库宕机或者严重到影响业务性能才会跟踪。跟踪指标可能是 GC 问题、锁问题、宕机问题。分析这类问题一般要查看活动会话、ALERT 日志、集群日志挖掘有用信息。
其次:当发现可能网络问题时,往往分析网络错误,但网络错误无法回溯历史,如果只是突发事件这里很可能就断了,结论止步于“可能”是网络问题引发。
再次:更有经验的 DBA,才能在故障期间去分析 NETSTAT -S 分析结果,并统计错误增量,最终挖掘到根因。
人工查找包重组这类隐蔽性能问题,想真正的实现精准定位,即便有经验的 DBA 专家,结合推送的监控指标和多年运维的经验,一步步排查相关组件,到推理怀疑到网络,至少需要耗时1小时,在业务已经濒临中断的情况下,DBA 的压力可想而知。zCloud 代替人工,通过对数据库全链路数据诊断的应用,从表象到根因,将问题定位和解决这一过程缩短到了10分钟以内,帮助 DBA 快速识别根因和解决问题,将处理效率提升6倍以上,不但大幅提升数据库运维管理水平,运维能力也更上一层楼。
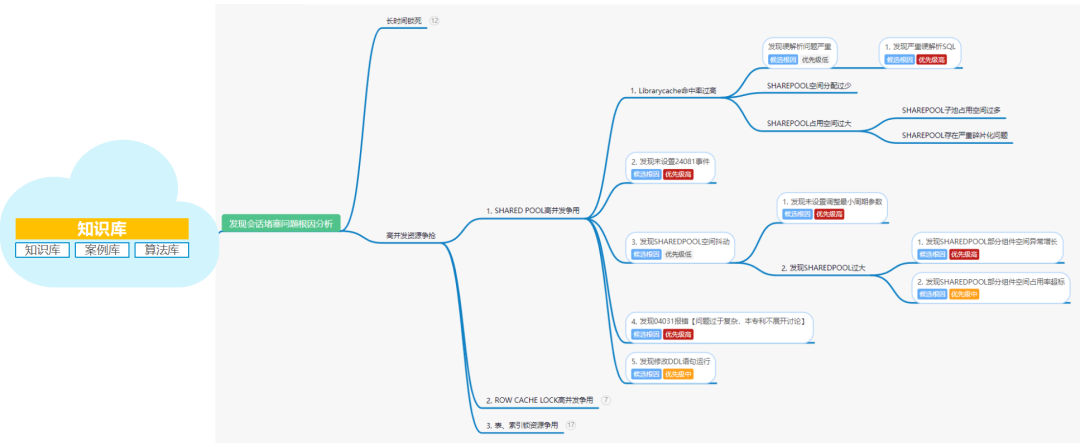
云和恩墨 zCloud 数据库云管平台,基于 WaaS(Wisdom as a Service,智慧即服务)理念打造知识库与智能诊断功能,将行业最佳实践和专家经验转化为平台能力,让高级“数据库专家”实时在线,有效保障数据库稳定高效运行。
WaaS 模型从数据到智慧,持续将专家经验代码化,为平台动态赋能:数据层面利用管理大数据,实现对数据库做精准画像,改变过去基于指标运维的不足;知识层面通过共建共享知识库,解决过去管理经验孤岛、样本不足的问题;智慧层面通过用户贡献个案、专家标注、机器学习三个来源生成知识点、案例、算法,实现经验代码化。
智能诊断——从一次数据库会话阻塞根因诊断看全链路数据智能分析
2022年7月30日
云和恩墨
648
警告!
晚上22:30左右,运维人员接到系统告警,发现系统业务响应极慢,随即发现数据库会话阻塞的问题,于是马上通知了 DBA 进行排查,希望能尽快使业务恢复正常。
DBA 紧急登录当前正在使用的 zCloud 系统智能诊断模块查看,通过系统告警的问题列表很快发现了问题所在:
-
告警列表中排在第一位最严重的问题是“等待/阻塞会话数过多或过长”(如下图);
-
进一步查看,点击该问题查看详情,发现当时数据库有47个会话被阻塞,占到52个活动会话的90%以上。



Increase value of below kernel parameter as mentioned below,
net.ipv4.ipfrag_high_thresh = 16M
net.ipv4.ipfrag_low_thresh = 15M

zCloud 数据库云管平台,身边的“数据库专家”

智能诊断, 精准定位问题根因
zCloud 智能诊断覆盖数据采集→问题感知→自动诊断→识别根因→故障自愈五个阶段。从数据采集开始,在不影响数据库稳定性的前提下,最大程度覆盖和优化采集指标,并通过一系列算法,过滤分级,收敛检测点,降低误报率等,破除浅层表象,同时进行事件关联,自动生成诊断关系树,层层深入,最终找到问题根因,并提出解决方案。

zCloud 知识库积累的最佳实践和专家经验为智能诊断动态赋能,持续提升平台的智能化诊断能力。