<< 返回文章列表
gs_dump 是 MogDB 中一个功能丰富灵活的数据库导出工具,在数据库的维护、迁移和开发中经常使用。该工具允许用户根据需要导出整个数据库或者数据库中的特定对象,如模式(schema)、表(tables)、视图(views)等。
近期有客户咨询gs_dump如何保证数据一致性?备份期间对数据库和表如何加锁?为了解答这个问题,顺便了解一下gs_dump的实现过程,本文对该工具的源码进行了一番解读。
由于无法查看到 MogDB 的gs_dump工具的源码,所以源码使用了gitee上用openGauss 5.0版本的gs_dump代码作为参考。
脚本路径:src/bin/pg_dump/
gs_dump的功能主要在pg_dump.cpp脚本中,同目录下还有pg_backup、pg_dumpall、pg_restore等功能脚本。从脚本名字上来看,这个脚本是继承自postgres。
下面通过分析pg_dump.cpp的main函数,从源码层面解读gs_dump 导出操作时的工作流程。
在getopt_dump函数中使用 getopt_long 来解析命令行参数,并根据解析结果设置相应的全局变量,存储各种选项,如压缩级别、输出格式、用户名等
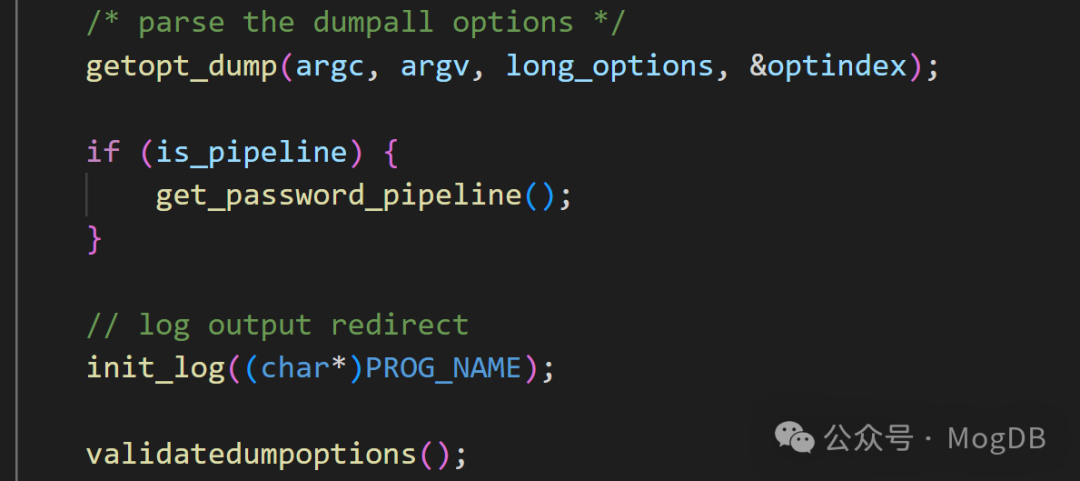
在getopt_dump 函数中,解析命令行的入参:

createArchive 函数接受了从命令行参数中解析出的输出路径,压缩等级等参数,创建输出文件。
ConnectDatabase函数使用给定的参数建立数据库连接,如果连接报错就清理输出文件;如果正常,则在fout对象中设置仅当前会话生效的参数。
再使用setup_connection 函数建立与数据库的连接,后面将会在此连接中执行导出。
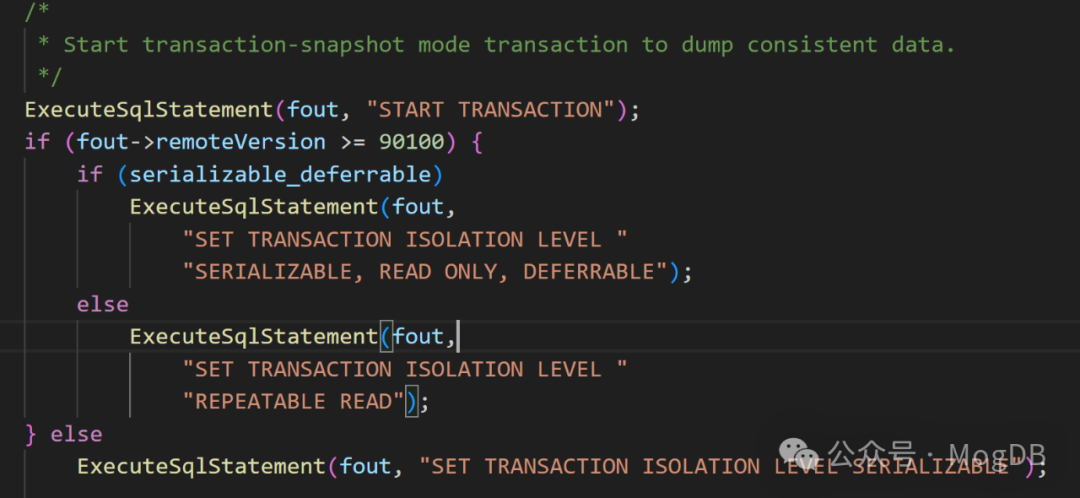
fout->remoteVersion >= 90100表示pg的版本大于9.1。
gs_dump 参数 --serializable-deferrable 可以控制导出事务的隔离级别。默认gs_dump事务的隔离级别为REPEATABLE READ,如果设置了serializable-deferrable参数,事务的隔离级别为SERIALIZABLE,但在Mogdb中,SERIALIZABLE等价于REPEATABLE READ,所以gs_dump事务的隔离级别始终REPEATABLE READ。DEFERRABLE允许一个只读串行事务延迟执行,即如果在导出之前,有读写事务处于活动状态,转储的开始时间可能会延迟等待读写事务结束,这样能保证使用的快照与之后的数据库状态一致。
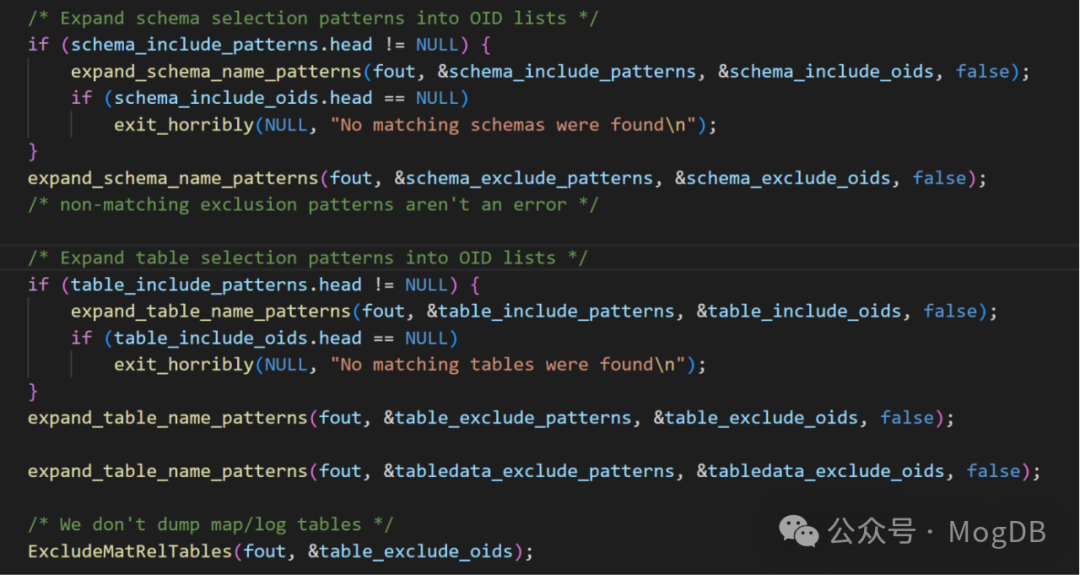
这部分代码使用expand_schema_name_patterns和expand_table_name_patterns 将要导出的schema和table 的oid保存在列表中。
添加schema时,schema_include_patterns参数来自于命令行参数-n,在expand_schema_name_patterns函数中,通过简单的查询pg_namespace视图,将schema的oid 添加到列表中。
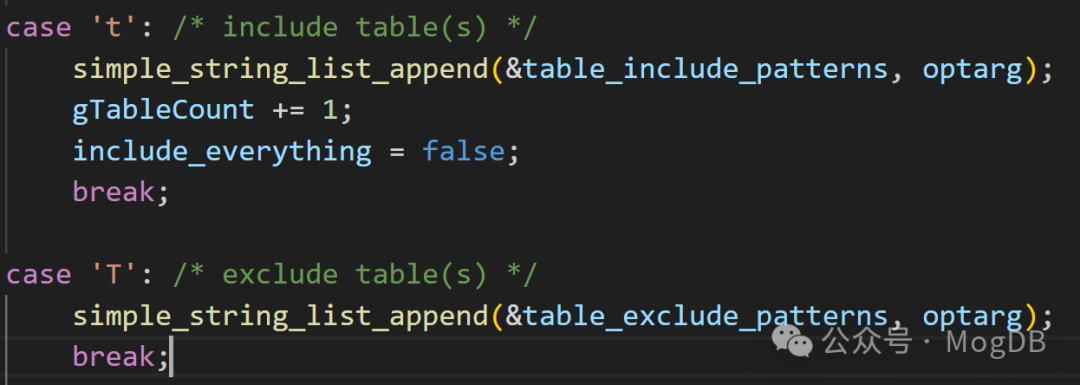
而添加表时table_include_patterns和table_exclude_patterns分别来自命令行参数-t 和-T,通过查询pg_class 和 pg_namespace,将oid 添加分别添加到导出类别和排除列表中。
扫描数据库并为要导出的所有对象创建DumpableObject结构。
根据每个对象的依赖关系,调用getDependencies函数,整理对象间的依赖关系,调用sortDumpableObjects来决定各个数据库对象导出的顺序。
这里主要调用了dumpDumpableObject函数,本函数根据要导出的对象类型,调用不同的导出函数进行处理。主要逻辑如下
以导出表为例,
dumpTable 函数只导出表定义,调用了dumpTableSchema生成表或视图的声明
dumpTableData函数导出表数据,根据命令行参数--inserts,选择使用copy命令导出还是导出成insert 语句
在执行COPY 命令时,会对表上加AssessShareLock锁,此锁能和除了ExclusiveLock以外的锁共存,也就是在执行copy命令不影响对表的增删改操作,只和DDL操作冲突。
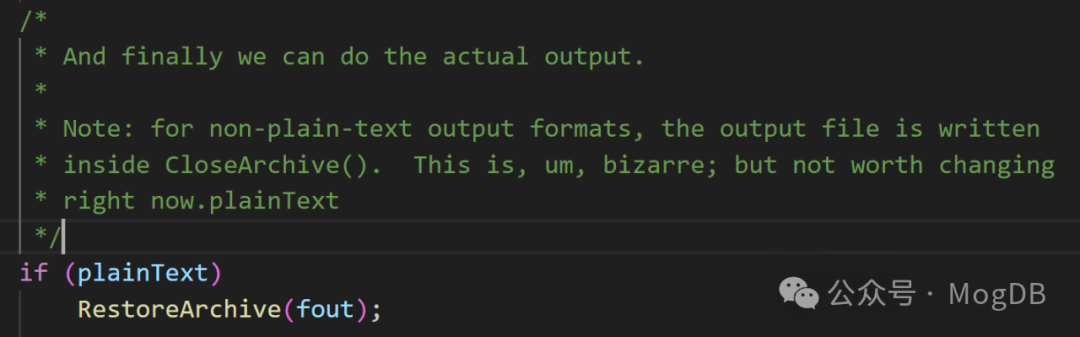
调用RestoreArchive函数,真正的导出数据。RestoreArchive函数在pg_backup_archiver.cpp文件中。
导出完成后,释放资源,退出导出任务:
以上通过对opengauss 5.0源码中pg_dump.cpp mian函数的解读,可以了解到在执行gs_dump 操作导出数据库对象时具体做了哪些工作。
MogDB 中gs_dump数据库导出工具源码概览
2024年7月9日
陈坤
537
背景
初始化和设置
-
包含必要的头文件并设置环境相关的配置。 -
定义各种宏和常量以进行操作。 -
声明全局变量和结构体用于处理用户输入、数据库连接和转储选项。
命令行参数解析
static void getopt_dump(int argc, char** argv, struct option options[], int* result)
{
int opt;
while ((opt = getopt_long(argc, argv, "abcCE:f:F:g:h:n:N:oOp:q:RsS:t:T:U:vwW:xZ:", options, NULL)) != -1)
{
switch (opt)
{
case 'h':
显示帮助信息
help(argv[0]);
exit(0);
case 'F':
设置格式
format = optarg;
break;
case 'p':
设置端口
port = optarg;
break;
其他选项处理
}
}
}创建输出文件,注册清理机制
连接数据库
errorMessages = ConnectDatabase(fout, dbname, pghost, pgport, username, prompt_password, false);
if (errorMessages != NULL) {
(void)remove(filename);
GS_FREE(filename);
exit_horribly(NULL, "connection to database \"%s\" failed: %s ",
((dbname != NULL) ? dbname : ""), errorMessages);
}
if (CheckIfStandby(fout)) {
(void)remove(filename);
exit_horribly(NULL, "%s is not supported on standby or cascade standby\n", progname);
}
if (schemaOnly) {
ExecuteSqlStatement(fout, "set enable_hashjoin=off");
ExecuteSqlStatement(fout, "set enable_mergejoin=off");
ExecuteSqlStatement(fout, "set enable_indexscan=true");
ExecuteSqlStatement(fout, "set enable_nestloop=true");
}
* Turn off log collection parameters to improve execution performance */
ExecuteSqlStatement(fout, "set resource_track_level='none'");
find_current_connection_node_type(fout);
Get the database which will be dumped
if (NULL == dbname) {
ArchiveHandle* AH = (ArchiveHandle*)fout;
dbname = gs_strdup(PQdb(AH->connection));
}
if (NULL == instport) {
ArchiveHandle* AH = (ArchiveHandle*)fout;
instport = gs_strdup(PQport(AH->connection));
}
if ((use_role != NULL) && (rolepasswd == NULL)) {
get_role_password();
}
setup_connection(fout);
static void setup_connection(Archive* AH)
{
建立数据库连接
PGconn *conn = PQsetdbLogin(pghost, pgport, NULL, NULL, dbname, username, password);
if (PQstatus(conn) != CONNECTION_OK)
{
fprintf(stderr, "Connection to database failed: %s", PQerrorMessage(conn));
exit(1);
}
AH->connection = conn;
}开启事务

添加导出schema和表

static void expand_schema_name_patterns(
...
if (patterns->head == NULL) {
return; * nothing to do */
}
query = createPQExpBuffer();
for (cell = patterns->head; cell != NULL; cell = cell->next) {
appendPQExpBuffer(query, "SELECT oid FROM pg_catalog.pg_namespace n\n");
...
}
destroyPQExpBuffer(query);
}
static void expand_table_name_patterns(
Archive* fout, SimpleStringList* patterns, SimpleOidList* oidlists, bool isinclude)
{
...
query = createPQExpBuffer();
for (cell = patterns->head; cell != NULL; cell = cell->next) {
appendPQExpBuffer(query,
"SELECT c.oid"
"\nFROM pg_catalog.pg_class c"
"\n LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace"
"\nWHERE c.relkind in ('%c', '%c', '%c', '%c', '%c','%c', '%c', '%c')\n",
RELKIND_RELATION,
RELKIND_SEQUENCE,
RELKIND_LARGE_SEQUENCE,
RELKIND_VIEW,
RELKIND_MATVIEW,
RELKIND_CONTQUERY,
RELKIND_FOREIGN_TABLE,
RELKIND_STREAM);
...
}
destroyPQExpBuffer(query);
}获取导出数据对象
tblinfo = getSchemaData(fout, &numTables);
if (fout->remoteVersion < 80400)
guessConstraintInheritance(tblinfo, numTables);
if (!schemaOnly) {
getTableData(tblinfo, numTables);
if (dataOnly)
getTableDataFKConstraints();
}
if (outputBlobs)
getBlobs(fout);获取依赖和排序
//获取数据库对象的依赖关系。依赖关系用于确保在导出数据库对象时,它们之间的顺序是正确的。
getDependencies(fout);
boundaryObjs = createBoundaryObjects();
//获取所有已知的数据库对象。
getDumpableObjects(&dobjs, &numObjs);
addBoundaryDependencies(dobjs, numObjs, boundaryObjs);
...
sortDumpableObjects(dobjs, numObjs, boundaryObjs[0].dumpId, boundaryObjs[1].dumpId);执行导出
for (i = 0; i < numObjs; i++) {
if (!dataOnly && dobjs[i]->dump && dobjs[i]->objType != DO_DUMMY_TYPE &&
dobjs[i]->objType != DO_PRE_DATA_BOUNDARY && dobjs[i]->objType != DO_POST_DATA_BOUNDARY) {
dumpObjNums++;
if (dumpObjNums % OUTPUT_OBJECT_NUM == 0)
write_msg(NULL,
"[%6.2lf%%] %d objects have been dumped.\n",
float((float(dumpObjNums * 100.0)) totalObjNums),
dumpObjNums);
}
dumpDumpableObject(fout, dobjs[i]);
}static void dumpDumpableObject(Archive *fout, DumpableObject *dobj)
{
根据对象的类型进行处理
switch (dobj->objType)
{
case DO_TABLE:
dumpTable(fout, (TableInfo *) dobj);
break;
case DO_INDEX:
dumpIndex(fout, (IndxInfo *) dobj);
break;
case DO_VIEW:
dumpView(fout, (ViewInfo *) dobj);
break;
case DO_TRIGGER:
dumpTrigger(fout, (TriggerInfo *) dobj);
break;
其他对象类型
/ ... }
}static void dumpTableData(Archive* fout, TableDataInfo* tdinfo)
{
...
if (!dump_inserts) {
/* Dump/restore using COPY */
dumpFn = dumpTableData_copy;
} else {
/* Restore using INSERT */
dumpFn = dumpTableData_insert;
}
...testdb=# SELECT pl.pid, pl.virtualtransaction AS vxid, pl.locktype AS lock_type,pl.mode AS lock_mode, pl.granted,
CASE
WHEN pl.virtualxid IS NOT NULL AND pl.transactionid IS NOT NULL THEN pl.virtualxid || ' ' || pl.transactionid
WHEN pl.virtualxid::text IS NOT NULL
THEN pl.virtualxid
ELSE
pl.transactionid::text
END AS xid_lock, pc.relname,
pl.page, pl.tuple, pl.classid, pl.objid, pl.objsubid,ps.usename,ps.application_name,ps.query
FROM pg_locks pl LEFT OUTER JOIN pg_class pc ON (pl.relation = pc.oid) left join pg_stat_activity ps on ps.pid = pl.pid
WHERE pl.pid != pg_backend_pid();
pid | vxid | lock_type | lock_mode | granted | xid_lock | relname | page | tuple | classid | objid | objsubid | usename | application_name
| query
----------------+----------+------------+-----------------+---------+----------+---------+------+-------+---------+-------+----------+---------+------------------+----------------------------------------
47858921375488 | 17/15218 | relation | AccessShareLock | t | | cct | | | | | | test | gsql
| copy cct to '/home/test/city.bat';
导出资源
释放资源