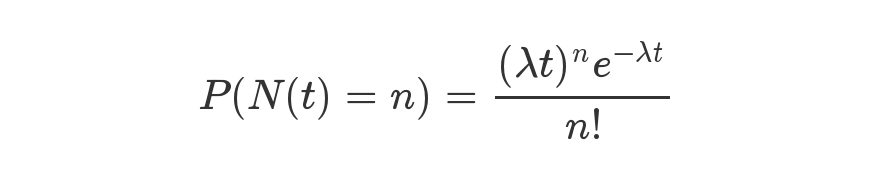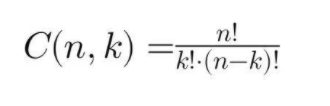有朋友可能会问,9个9的数据可靠性的理论值(即1e-9的数据损坏概率)是如何计算得来的?本文详细讲解一下。
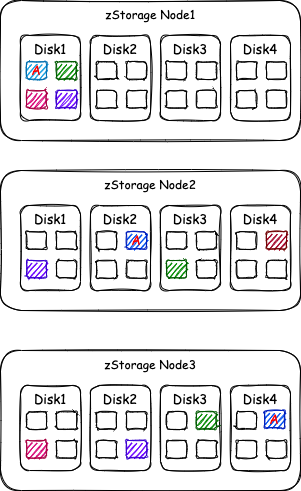
直觉上,对于3副本存储池,数据丢失/损坏的概率,就是“同时发生3块磁盘损坏”的概率,我们口头上也经常这样表达。先来看这个“同时”指什么?它是绝对意义上的同时发生,还是在1秒之内发生叫“同时”,亦或是1分钟之内发生叫“同时”?这个“同时发生3块磁盘损坏”可以定义为“在第一个磁盘损坏后,还没有完成该盘的重构的这段时间内又相继损坏了两个盘”。对于 zStorage 的标准3副本存储池而言,假设磁盘都是4TB大小,磁盘损坏后重构的时间为60分钟,那么:
-
磁盘1损坏,马上将该磁盘离线,开始重构。
-
假设又过了10分钟,磁盘2损坏,该磁盘马上进入离线状态,开始对该盘的副本进行重构。
-
在从磁盘1损坏开始的60分钟(即60分钟的磁盘重构时间)内,磁盘3损坏,这个时间磁盘1的重构还没有完成,磁盘2也还在重构中,这个时候磁盘3再损坏,整个存储池就坏了。