大家好,很荣幸与大家分享日常运维中的交付安全。我想以一次客户现场的经历作为引入:当时客户技术主管正处理HA软件故障,虽然不熟悉这款软件,但他还是通过现场查手册和做实验等方式,成功解决了问题。我夸赞他技术能力,他却说:“这次虽然把问题解决了,但我更希望团队别成‘救火队’,而是在平时就能发现隐患,定期演练和复盘。”
这让我想起扁鹊三兄弟的典故:最高明的医生往往是在病未显时就能够治好。运维也是如此——最好的安全交付,应该是把隐患扼杀在萌芽里。
在数字化时代,数据库承载关键业务数据,其安全性关系到企业稳定和声誉。但因操作失误、权限混乱、配置缺陷等,安全事件频发,轻则数据泄露,重则业务中断,损失巨大。接下来,我将基于真实案例,剖析运维中常见的安全风险——权限管理、数据泄露、操作隐患、合规挑战——并总结可落地的防范措施,帮助DBA团队规范流程、提升安全,确保数据资产平稳运行。
DBA工作的特殊性
1.核心重要性
作为企业关键信息基础设施,承载核心业务数据资产
2.高可用要求
需保障7x24小时不间断稳定运行
3.影响范围广泛
横向影响:涉及多业务部门协同运作
纵向影响:可能波及市级/省级业务系统
社会影响:关系国计民生关键领域
4.运维特殊性
变更窗口:主要安排在凌晨低峰时段
工作强度:高频次夜间作业带来的疲劳挑战

1
一个真实的凌晨运维经历:某生产数据库在例行启动时直接报出ORA-01177: database file 6 cannot be opened,进程随即中止。Alert日志中唯一的线索是“file does not match dictionary”,指向第6号数据文件,可在上千个文件中,仅凭这一条信息来找寻问题原因,使团队一度陷入迷茫。
我们首先从两个角度入手定位:在数据库控制文件中,第6号文件记录的块数为1279;而在操作系统层面,扣除文件头开销后,实际文件块数是1280。那一块的差异,揭示了完整性校验失败的根源。进一步与客户沟通后才得知:该文件很早之前被置于offline,归档日志也已被误删。为了重建控制文件,客户手工插入了一条字典记录,却因缺少日志基础无法验证正确的块数和SCN,从而将错误元数据写入字典,导致字典与物理文件“走失”,启动时自然无法通过校验。
面对故障,我们尝试过10046跟踪、errorstack分析,也尝试过导出全库数据字典,希望借此重建或修正元数据,但都无法打通控制文件与物理文件头的不一致。
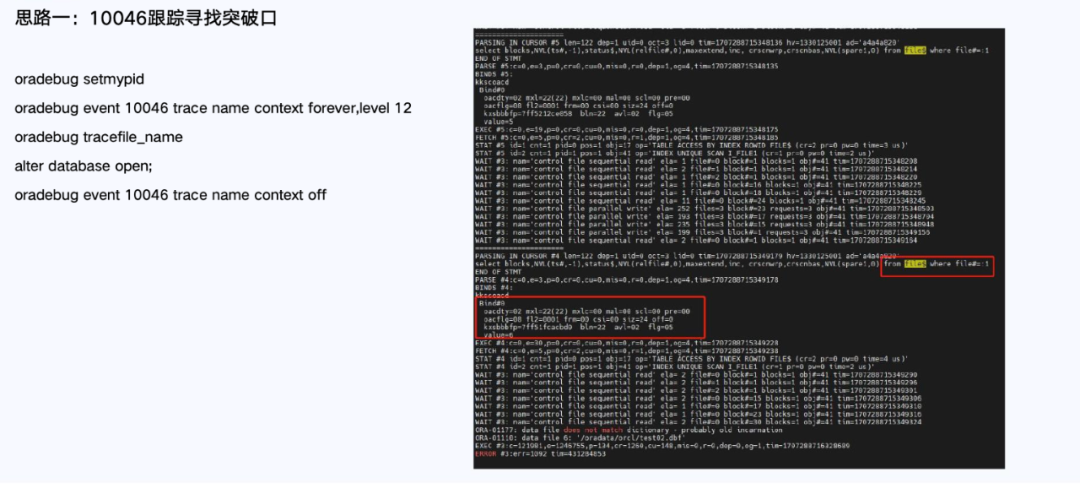
思路一:10046跟踪寻找突破口
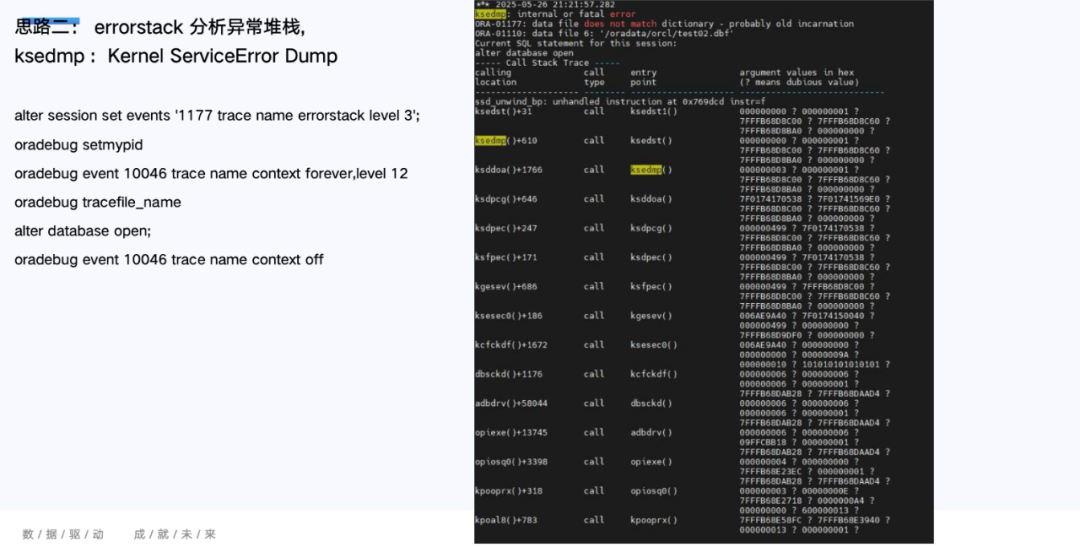
思路二:errorstack分析异常堆栈
紧急之际,我们启用了低级别修复利器——BBED(Block Browser and EDitor)
-
在控制文件中,将第6号文件的块数由1279调整至1280;
-
同步更新该文件的创建SCN、表空间ID与相对区号等元数据;
-
重启数据库,故障校验一举通过;
-
最后,将第6号文件执行ALTER DATABASE DATAFILE … ONLINE,恢复全量服务。
整个过程不到半小时,核心业务得以快速恢复,避免了长时间的中断风险。
从这个案例中,我们可以深刻体会到,可靠的备份是运维的基石:一旦缺失或过期,业务恢复的成本可能是无法承受的。同时,任何手工对数据字典的增删改操作都需谨慎,稍有不慎便会破坏控制文件与物理文件的协同一致。掌握低级别修复工具如BBED,能够在紧急关头对症下药,缩短故障恢复时间;而定期演练灾备与元数据修复流程,则是让团队在真正事故面前沉着冷静的关键。
规避此类安全事件的建议
-
有效的备份重于一切;
-
对生产环境保持敬畏,不放过任何性能波动疑点,不想当然和轻视任何数据操作,针对任何业务数据库的操作都不能草率,在接触数据时都不能掉以轻心;
-
禁止直接dml数据字典;
-
变更操作需要编写完善的变更方案,经过验证、审核,并得到客户审批同意后,在业务低峰期操作;
-
变更必须制定回退方案,不走单行线,确保出现异常时能够将系统恢复原貌;
-
出现超出常规、无法把握的问题时要保护现场,寻求支援,避免无序尝试带来的数据损失。
运维的最高境界,是把火种扑灭在萌芽中。平日里多做隐患排查与演练,才能在凌晨的“十万火急”时刻,依然从容应对。希望这个案例能为各位带来启发:防患未然,方显运维真功夫。
2
接下来分享的第二个案例,是一次数据文件迁移过程中遇到的挑战与我们的应对思路,希望对大家有所启发。
客户提出需求:将本地目录下约785个数据文件(总量近700GB)搬迁到新的共享存储上。按常规做法,关库后直接将所有文件拷贝到目标目录,再通过重建控制文件让数据库识别新路径即可上线。但在检查源目录时,我们发现多处同名文件散落于不同子目录下,例如USER01.DBF在多个文件夹中重复出现,且部分文件名中含有空格或特殊符号——若一股脑拷贝到同一目录,无疑会导致文件互相覆盖,甚至丢失关键表空间数据。
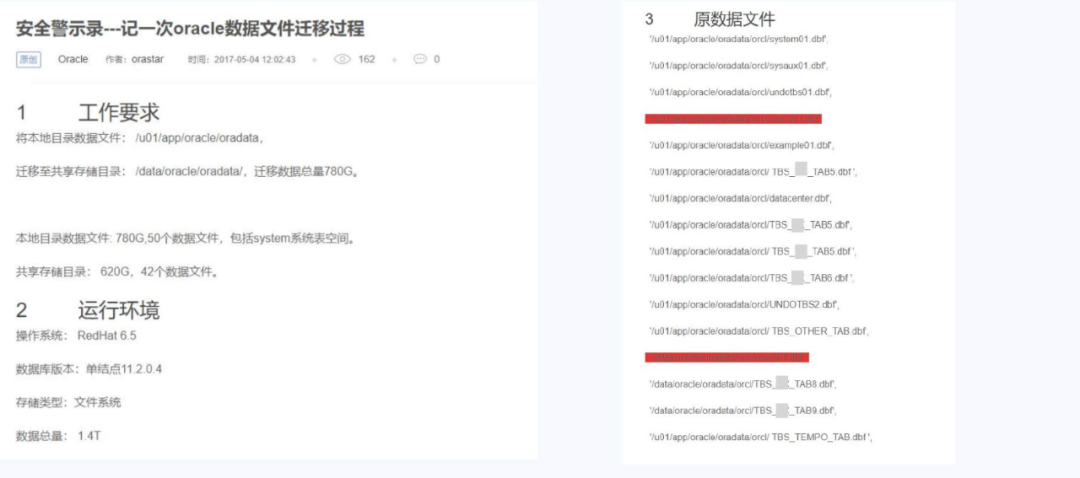
数据文件迁移的要求与环境
意识到风险后,我们立即中断操作,调整方案:
-
保持原有目录结构:在共享存储上为每个源子目录新建同名子目录,确保文件拷贝后仍与原路径一一对应;
-
分批验证拷贝结果:先在测试环境或小范围目录下试拷贝、校验文件校验和与大小,再批量推进,避免一次性错误放大;
-
备份与回退预案:在源存储中对所有数据文件做物理级快照备份;一旦新目录文件有误,可快速恢复原状;
-
多级审批与演练:拟定详细迁移方案,包含文件列表、目录映射表和验证脚本,经团队内部复核、客户审批后,于业务低峰期演练一遍,确认无误后才正式执行。

原迁移计划与最终迁移方案
最终,迁移工作顺利完成:所有数据文件在共享存储上重现原始结构,重建控制文件后,数据库平滑启动。
此次经历再次提醒我们,对生产环境的每一次变更都必须怀有敬畏之心——不走捷径,不轻视任何细节。保持目录一致性、严格验证与充分备份,是保障海量文件迁移安全的关键。希望这个案例能为各位在类似场景下提供实用参考。
3
前面两个案例偏向于技术处理和故障应对,而这个案例则更多是在提醒我们——运维安全的“坑”,有时候就藏在你最熟悉的工具里。这是我刚做DBA时亲身经历的一次操作“惊魂”,也让我对交付安全有了更深刻的认识。
当时我们使用一种PL工具,可以同时连接多个数据库环境:测试、准生产、生产等,但UI设计存在明显问题——它默认显示连接名称,而不是实际的数据库连接目标。
某次我刚做完测试联调操作,打算清理测试数据,便习惯性地用该工具执行了DELETE操作。可就在我点击执行前几秒,我突然意识到连接目标不太对,赶紧停下确认——果然,界面显示的是“测试库”的连接名,但实际连接的是生产库。
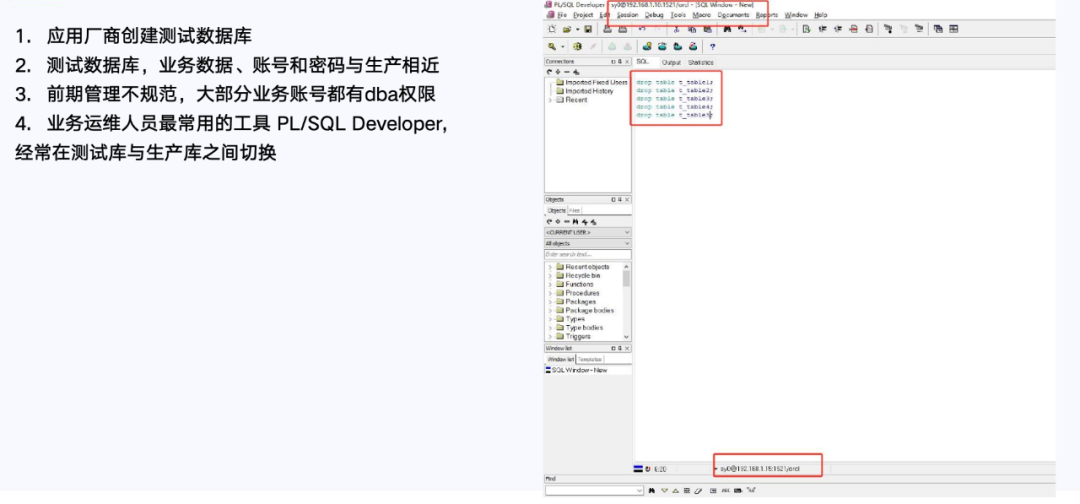
PL/SQL工具使用造成误删除表
这次操作虽然没有酿成事故,但却让我冷汗直流。之后我反复思考这个问题,背后暴露的是几个关键风险:
-
环境隔离不彻底:测试账号可以连接生产库;
-
工具设计不规范:显示的是连接“昵称”,而不是实际数据库地址或角色;
-
权限管理混乱:很多测试账号直接拥有DBA权限;
-
操作时间不安全:常在凌晨作业,易疲劳、易出错。
这让我第一次意识到,误操作往往不是技术能力不足造成的,而是系统性问题堆积的结果。特别是凌晨三点这种“认知最低谷”的时间,操作失误的概率大大增加。
很多一线DBA朋友都说,科比说过一句话:“你见过凌晨四点的洛杉矶吗?”作为DBA,我们经常见到凌晨1点、2点、3点、4点——但不是为了训练,而是在上线窗口、事故抢修、任务调度的压力下,强打精神支撑工作。相比科比的早起,我们更多的是熬夜+疲劳作战,这本身就是运维工作的一个“隐性风险”。
这次“惊险一刻”之后,为保障交付安全,我们团队从多个维度进行了规范化建设:
-
在工具层强制展示真实环境标识,并增加执行确认;
-
权限上实现测试账号与生产库隔离,禁止管理员权限滥用;
-
操作层面全部接入堡垒机审计,确保可追溯;
-
高风险操作原则上避免凌晨执行,并要求双人确认;
-
同时统一排查弱口令,建立标准化操作规范,配合定期培训和复盘,全面提升团队的安全意识与防护能力。
规避此类安全事件的建议
-
有效的备份重于一切;
-
测试和生产环境隔离,数据网络隔离。数据库应处于应用系统最后端,避免将其置于对外的访问连接之下,并且绝对不能在生产环境进行测试;
-
严格管控权限,明确用户职责。遵循最小权限授予原则,避免因为过度授权而带来的安全风险;明确不同的数据库用户能够用于的工作范围,防范和隔离风险;
-
密码策略强化,防范弱口令带来的安全风险,定期更换密码,同时生产和测试环境严格使用不同的密码策略。
-
在操作数据库时,必须使用数据安全操作工具,留存操作记录和日志,避免使用PL/SQL Developer、SQL Developer、SQL*Plus等工具直连数据库进行操作;
-
不建议使用PL/SQL登记账号密码功能。
这次经历也让我真正认识到,DBA的价值不仅体现在技术能力上,更体现在“能守住红线、不越底线”的安全责任感。正如盖总在《数据安全警示录》中所说:我们应始终以“数据的保护者”自居,而非窥探者、窃取者或破坏者。理智与情感分离,以成熟铸就职业操守,不将情绪带入系统之中。最后我想说,唯有始终坚守这份责任与底线,才能真正扛起DBA的使命。

《数据安全警示录》