从被动救火到主动掌控:数据库应急响应的3个效率密码
在数据驱动的时代,数据库已成为IT系统的核心命脉。但残酷的现实是,75%的严重业务中断源于未被及时发现的数据库隐患,超过60%的数据库故障因未能提前预警而升级为严重事故。
想要将故障平均修复时间缩短80%,关键在于建立一套高效的应急响应体系。通过“精准告警→快速分析→查杀阻塞”三个核心环节的闭环管理,结合智能化工具的赋能,就能让数据库故障处置从被动应对转向主动掌控。
精准告警:告别风暴,让有效信息直达责任人
告警是故障处置的第一道防线,但传统监控工具的“告警风暴”往往让运维人员陷入信息汪洋。大量重复、无关的告警信息不仅无法提供有效指引,反而会掩盖真正的故障隐患,导致关键问题被遗漏,往往错过最佳处置窗口。
想要突破这一困境,精准告警的核心必须围绕“去芜存菁”展开——既要过滤无效信息,又要确保关键告警精准触达。这就需要一套兼顾分类分级、智能收敛与精准分派的完整机制,而云和恩墨的Bethune X智能监控巡检平台正是通过这样的设计,彻底解决了告警泛滥的行业痛点。
平台采用“阈值告警+健康度建模”的双重智能模式,彻底解决告警泛滥问题。平台首先对告警进行分类分级,按性能类、容量类、可用性等维度分类,按警告、严重等级别分级,让运维人员能快速判断故障紧急程度。在此基础上,通过多重收敛策略实现告警“瘦身”:按时间间隔、容忍时间过滤重复告警,用高级别抑制低级别告警,按业务对象聚合多维度告警,避免同一故障引发海量通知。
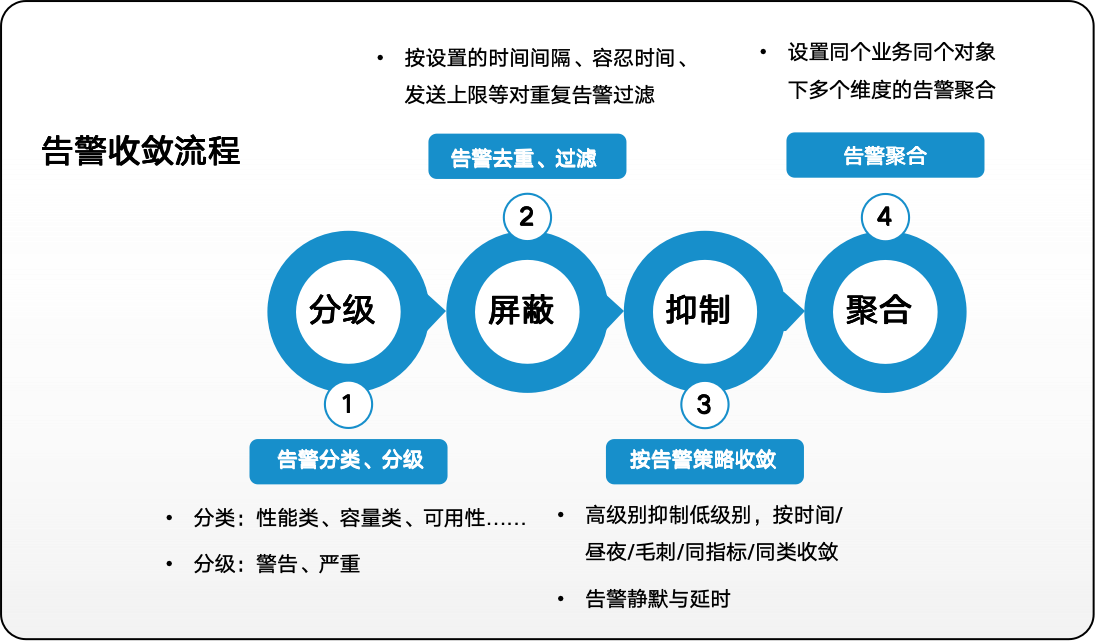
为了确保告警不被遗漏且精准触达,平台支持邮件、企业微信、飞书、钉钉等多渠道通知,可根据企业组织架构精准分配告警责任,让不同职责的运维人员只接收自己负责范围的告警信息。同时,告警内容包含集群/数据库名、详情链接,还可设置静默时间、延迟通知和自动升级机制,既减少不必要的干扰,又能保障严重故障得到及时响应,让运维人员能够精准接收关键信息,为后续处置节省宝贵时间。
快速分析:全链路数据支撑,精准定位根因
告警触发后,故障处置的效率就取决于根因定位的速度。传统排查方式的痛点十分突出:运维人员需依赖个人经验,从分散的指标、日志中拼凑线索,不仅过程繁琐,还容易因信息碎片化导致误判。尤其在复杂架构环境下,单一指标往往无法反映故障全貌,更需要一套能整合全链路数据、提供多维分析的智能化工具。
想要实现快速精准的根因定位,核心在于两点:一是拥有全面、实时的全链路数据采集能力,二是具备基于专家经验的智能化分析模型。Bethune X正是围绕这两点,构建了从数据采集到分析的完整闭环,让故障根因无所遁形。
平台以数据库为中心,构建了从集群到数据库的全链路指标采集体系,覆盖服务器硬件、操作系统、中间件、数据库、应用服务等多层级。平台整合了300+数据工程师的专家经验,固化数千条指标采集规则,支持高频(10秒)、中频(30秒/1分钟/5分钟)和低频(10分钟及以上)的分档采集,既能保证实时性,又能降低系统开销。这些指标不仅包括CPU、内存、磁盘等基础资源数据,还涵盖慢SQL、TOP SQL、执行计划、锁阻塞等数据库核心性能数据,形成完整的数据库运行画像。

在数据分析层面,平台采用集群视角建模,清晰展示实例与实例之间、实例与系统之间的关系,避免孤立看待单个指标。通过调用拓扑、时间线参照、元数据分析、日志收集等多维联动,结合TOP SQL排序、性能对比、执行计划分析等功能,运维人员可以快速锁定故障范围。例如,当出现性能异常时,平台能自动筛选出问题时间段内的TOP SQL,展示其执行计划、等待事件占比和CPU占用情况,帮助运维人员在分钟级内判断是SQL性能问题、资源瓶颈还是配置异常,彻底告别盲目排查。
查杀阻塞:一键处置,快速恢复业务
找到故障根因后,能否快速采取有效措施恢复业务,是应急响应的最终目标。在数据库故障中,会话堆积、锁阻塞是常见的紧急场景,若不能及时处置,可能导致业务响应停止,造成更大损失。此时需要的是简单、直接、高效的处置手段,让运维人员无需复杂操作就能快速止损。
面对这类紧急场景,高效处置的关键在于“简化操作、精准发力”。Bethune X提供了直观的会话管理功能,能够快速发现导致系统故障的TOP会话堆积问题,以及锁阻塞的源头——通过树形结构展示阻塞关系,清晰标识出阻塞根源会话。针对这类紧急情况,平台支持“杀掉会话”和“批量杀会话”操作,运维人员无需手动输入复杂命令,只需一键操作就能快速终止异常会话,解除阻塞状态,恢复数据库正常运行。
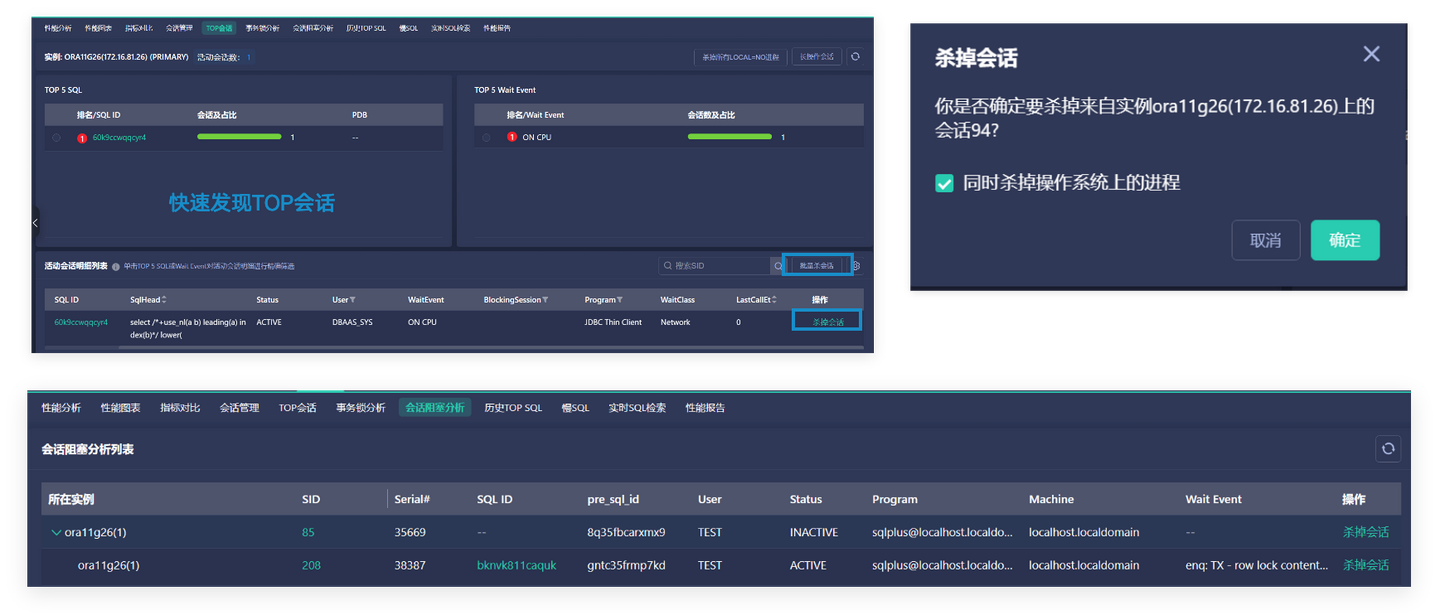
这种可视化定位+一键处置的模式,避免了传统处置过程中繁琐的命令输入和人工判断,让即使是初级运维人员也能高效处理复杂的阻塞问题。同时,平台会记录整个处置过程,包括会话信息、查杀时间、操作人等,为后续的根因溯源和优化提供完整依据,实现“处置-记录-优化”的闭环。
全流程保障:从应急处置到持续优化
“精准告警→快速分析→查杀阻塞”的应急响应闭环,离不开事前预防和事后优化的支撑。Bethune X并非只关注故障发生时的处置,而是构建了“事前预防-事中处置-事后优化”的全流程保障体系,让数据库持续保持在最佳状态。
事前,平台通过自动化深度巡检提前发现潜在风险,巡检内容覆盖健康度、库表、日志、备份容灾、空间资源等多个维度,效率较人工巡检提升10倍,可规避80%的数据库问题;通过智能容量预测,基于当前使用情况和历史趋势建模,提前预判空间耗尽风险,并支持一键扩容或自动扩容,避免因容量问题导致业务中断;通过主动优化慢SQL,避免性能问题积累放大。事后,平台会对历史告警进行汇总分析,针对高频出现的告警项优化配置,对数据库存在的共性问题进行整改;通过根因溯源,将解决方案转化为自定义巡检项,从源头规避同类故障再次发生。
从被动救火到主动防控,从经验驱动到数据驱动,Bethune X以300+数据工程师的专家经验为基础,将数据库运维的最佳实践固化为产品能力。正在重新定义数据库运维模式,让每个组织都能轻松掌控数据库状态,为业务持续运行保驾护航。