SQL性能持续优化,DBA需关注的5个重要环节

在数据库运维的日常工作中,SQL性能问题的处理常常呈现出一种被动与碎片化的状态。当业务系统出现响应缓慢或超时告警时,DBA往往需要匆忙介入,从海量日志中筛选慢SQL,再凭借个人经验进行初步分析与优化尝试。这一过程不仅耗时耗力,更在多个环节存在显著痛点:
-
问题发现依赖事后告警:通常只有SQL执行缓慢达到阈值后才会被察觉,此时业务可能已受到影响,缺乏事前预警与主动发现机制。
-
根因定位困难且低效:面对一条慢SQL,DBA需手动关联执行计划、索引状态、锁信息、资源使用等多维度数据,分析过程如同“大海捞针”,严重依赖个人经验与熟练度,排查效率低下且易误判。
-
优化建议缺乏体系支撑:优化方案往往基于经验判断,难以全面评估潜在影响,有时甚至因考虑不周引发新的性能问题,如锁阻塞或索引冗余。
-
变更上线存在运维风险:优化脚本的执行多在业务运行期间手动进行,缺乏统一管控、风险评估与回滚机制,容易造成二次故障。
-
效果验证凭感觉、无闭环:优化后往往缺少持续的性能跟踪与量化对比,无法确认优化是否真正生效,也难以积累可复用的优化经验。
这些痛点共同导致传统SQL优化工作陷入“响应迟、分析慢、实施险、验证难”的困境,不仅消耗大量人力资源,也难以形成可持续的性能管理体系。因此,构建一套覆盖“发现→分析→建议→上线→验证”的全流程闭环机制,成为打破当前被动局面、实现SQL性能持续优化的关键突破点。
1
SQL性能问题的解决,最佳时机是“问题萌芽期”。然而普遍的事实是:传统依赖“阈值告警”的被动方式存在明显滞后性,且往往只能捕捉到已持续恶化的“显性问题”,而大量潜在的性能衰减、新增低效SQL或结构性隐患(如索引失效、空间不足)则悄然积累,直至在某次业务高峰时突然爆发。
因此,优化的首要突破点在于将“发现”动作大幅提前,从被动响应告警转向主动、持续的性能洞察。这意味着需要建立一套覆盖实时监控与自动化巡检的发现机制,其核心价值并非保证“拦住”每一个问题,而在于提前暴露风险、系统化扫描隐患、为分析根因争取时间。
云和恩墨的数据库监控巡检工具Bethune X就具备“实时监控+自动化巡检”的双重发现机制。它从集群到数据库进行全链路全维度指标采集,精准构建数据库画像。采集频率可根据需求分档设置——高频(10秒)监控实例状态,中频(30秒-1分钟)跟踪等待事件、连接数,低频(10分钟以上)统计空间、数据文件。这种高密度、低开销的采集模式,能实时捕捉TOP SQL、性能衰变语句,甚至提前识别新增低效SQL。
自动化巡检则是将“被动等待”变为“主动出击”。用户可自定义巡检场景,系统基于专家预设项自动扫描索引失效、查询低效、空间不足等隐患,巡检效率提升10倍。巡检报告通过邮件主动推送,附带健康度评分和问题详情,让DBA在业务受影响前就拿到风险清单,采取必要行动。

2
找到问题SQL后,传统排查往往依赖DBA经验,不仅技术门槛高,耗时耗力还容易出错。Bethune X的深度下钻分析能力,让根因定位从“经验驱动”转向“数据驱动”。
针对问题SQL,平台会自动拆解执行计划,关联等待事件、表结构、索引信息、系统资源占用等多维度数据,直观展示全表扫描、索引失效、锁阻塞等核心问题。对于复杂的锁阻塞场景,平台能直接呈现阻塞源头,无需手动拼接日志;通过时间线对比、拓扑关联分析,还能快速还原性能衰减轨迹,精准判断是数据量增长、SQL逻辑变更还是系统资源瓶颈导致的问题。这种“一站式分析”让故障定位时长缩短80%,即使是初级DBA也能快速找到症结,无需依赖资深专家。

3
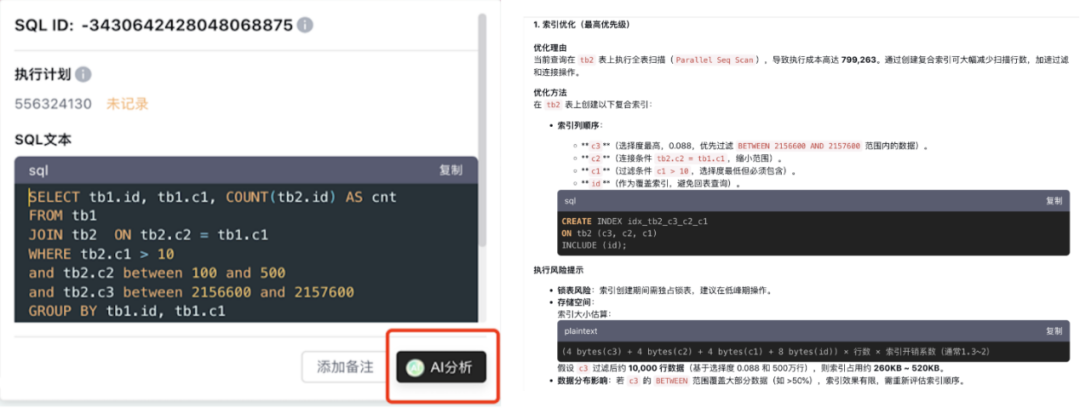
优化建议的质量,直接决定优化效果。Bethune X的智能诊断引擎将大语言模型(LLM)、检索增强生成(RAG)技术与云和恩墨300+DBA十余年积累的知识经验相结合,给出的建议兼具专业性和可行性。
针对低效SQL,平台会自动生成具体的优化方案:索引创建建议会综合考虑字段选择性、表大小、数据分布等因素,避免盲目建索引;SQL改写建议直接提供可执行语句,同时对比不同方案的预期效果,帮助用户选择最优解。对于不熟悉的问题,还能通过智能问答功能查询知识库和同类案例,快速理解优化逻辑,不仅让初级DBA能完成专业级优化,还能大幅缩短优化周期。
4
优化方案再好,上线失控也会引发灾难。建议DBA团队建立一套严谨的变更管理流程,以将潜在风险控制在最小范围。
首先,任何可能影响性能的SQL或索引变更,都应计划在业务低峰期执行,并提前通知相关方,以尽可能降低对核心业务的影响。
其次,执行前应进行充分的风险评估,手动或借助Bethune X这类工具检查变更涉及的表空间是否充足、主备延迟是否在可接受范围,并明确回滚方案。
再次,变更执行需经过申请、审批、执行、复核等完善的流程,不同角色各司其职,避免误操作。
最后,应在独立的测试环境中进行充分的预发布验证。通过将变更方案在模拟真实负载的测试环境中执行,并利用如Bethune X等监控工具,观察系统是否出现新的Top SQL、异常等待事件或资源使用波动等潜在问题。这种基于监控数据的预判,能够帮助DBA识别变更可能带来的隐藏风险,从而在正式上线前进行调整与优化。只有经过测试环境充分验证且监控指标稳定的变更,才可正式在生产环境中上线。
5
优化上线不是终点,持续验证才能确保效果长久。因此,构建一个量化的效果跟踪体系至关重要,这能确保优化收益可衡量、可追溯,并为持续优化提供数据依据。
在变更完成后,DBA就应立即启动效果验证——借助Bethune X有针对性地监控被优化SQL的执行时间、资源消耗(CPU、I/O)以及相关业务接口的响应时间等指标,与优化前的基线数据进行对比,生成清晰的收益报告。
更重要的是,DBA应有意识地建立起持续监控机制,将优化后的SQL纳入重点关注列表,设置适当的性能衰减告警。一旦指标出现退化,能够及时察觉并分析原因,判断是优化方案不彻底、数据量增长还是出现了新的依赖问题。
此外,推动经验沉淀十分必要。将本次优化过程中验证有效的策略(如某种索引规则、改写模式)转化为团队知识库条目或巡检规则,使其能自动化地应用到其他类似场景中,从而将一次性的优化行动,转化为团队可持续提升的运维能力。Bethune X可迭代的私域知识库就为这种团队运维能力和自身智能水平的提升提供了重要保障。
SQL性能优化的能力构建,本质上是运维理念的升级——不再是“出了问题再解决”,而是“提前洞察、精准解决、持续优化”。而这一切的落地,离不开工具对专家经验的固化和智能化能力的赋能。当优化流程被标准化、自动化、可追溯化,DBA才能真正摆脱“救火队员”的角色,成为业务发展的“护航者”。