声明:本文作者为华东某大型汽车零部件厂商的信息化负责人于涛(化名),出于项目保密的要求,文中对企业名称、工作人员、指标数据等做了模糊化处理。文章内容及配图经云和恩墨润色处理。
2025年7月初的一个下午,三点半,正是车间早班结单冲刺的时候。
我盯着MES系统的大屏,进度条标绿,产出达成率维持在98%。按照这个节奏,今天早班的生产交付没问题。我刚想喝口水,准备去隔壁二期产线看看新接入的EOL(下线检测)设备,兜里的手机突然震了。
“Critical Alert: MES_DB_Transaction_Blocked. 阻塞时长已超30s,受影响会话数激增。”
我心里一沉,知道这条告警意味着什么——在汽车零部件的生产中,30秒的延迟约等于宕机。我们的MES系统是典型的“一拉多”架构,这条链路一旦“卡死”,意味着排产计划发不下去、工序过站读不了码、质检数据对不上、甚至连最后一步的自动报工都会停摆。
我快步走向IT运维办公室,同时给DBA小周(化名)打了个电话。
“核心库可能出问题了,你赶紧看一下。”

那个让车间差点停摆的下午
后来复盘,小周说那天的问题其实早就有苗头。
当天上午,系统其实出现过一次短暂的工单下达延迟,大概5秒左右,持续了不到一分钟就自行恢复了。当时生产端没投诉,我们也没太在意——生产旺季系统偶有抖动,也算正常。
但实际上,那是数据库性能衰减的信号。
当时有一条报表关联查询的SQL,随着业务量增长,执行时间从原来的2秒慢慢爬升到了8秒、15秒、30秒。增量不大,没有触发告警阈值,但它逐渐占满了连接池资源,导致新的工单下达请求开始排队。后来的延迟其实是被前面积压的请求拖累的。
小周后来排查了整整三个小时。查日志、查执行计划、查索引使用情况、查表空间——就是这么多步骤,一项一项地找问题。最后定位到是一个季度末的大批量历史数据归档后,某张关联查询表的统计信息没有及时更新,导致数据库优化器选错了执行路径。
三个小时,生产系统勉强撑着没崩,但那天加班的小周最后走的时候脸色很难看。“说实话,如果当时能早点发现、或者分析过程更快一些,不至于这么被动。”小周后来跟我说。

我们后来是怎么做的?
今年,我们对数据库运维的思路做了调整。不是换什么大系统,而是把数据库性能管理这套流程重新梳理了一遍。主要是抓五个环节:
1. 把发现提前:从被动等告警,到主动扫隐患
设备驱动型工艺的制造场景有个特点——生产是连续的,系统不能停。
等出问题了再告警,那是常规思路。但对于MES、ERP这类系统来说,等你感知到问题的时候,车间可能已经开始积压工单了。
所以第一步,我们把监控的颗粒度提上去。以前只能看到“数据库能不能连上”,现在要能看到每条SQL的执行时间、等待事件、新增的慢查询等等。
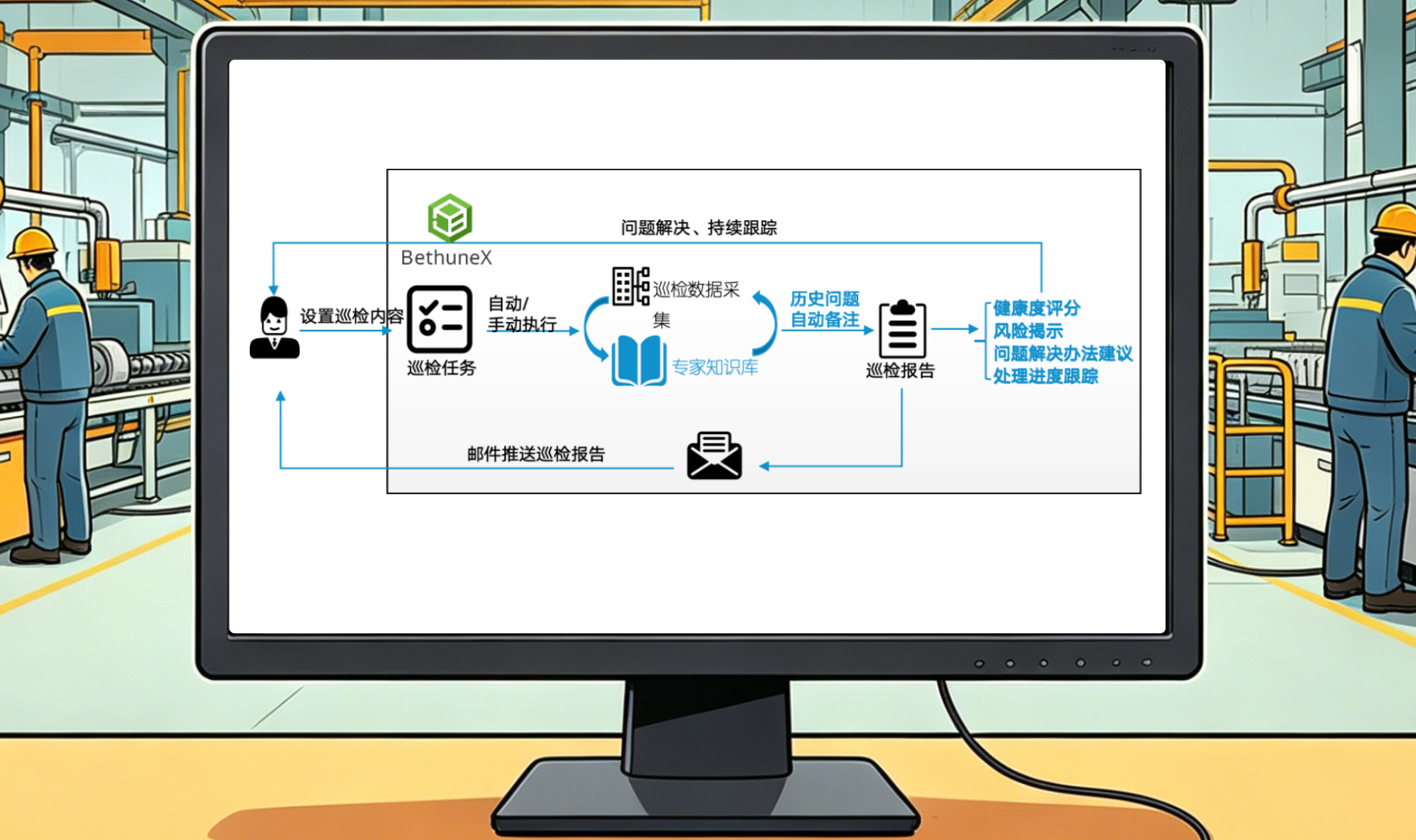
云和恩墨的数据库监控巡检平台Bethune X很好地满足了我们的需求。它的“实时监控”主动机制能够做到事前预防,提早发现SQL风险苗头;事中快速定位并解决问题;事后追踪效果,以便持续优化改进。
同时,“自动化巡检”是Bethune X的另一主动机制。做DBA的都知道,巡检这件事几乎每天都要做,难度不大但很耗精力。现在我们通过Bethune X就可以每天定时、自动地去扫一遍索引有没有失效、有没有出现新的TOP SQL、性能有没有呈现恶化趋势、空间够不够等。最后生成的巡检报告会通过邮件主动推送给我们的DBA,附带健康度评分和问题详情,让DBA在业务受影响前就拿到风险清单,采取必要行动。上个月的一次巡检中就发现了一条新增的低效查询,执行时间从几百毫秒慢慢爬到了几秒——查了一下,是因为当时上了一套新的质量追溯模块,数据关联逻辑变了。我们及时改了索引,问题没扩散到生产高峰期。
2. 分析要准确:从“大海捞针”到“一站式定位”
去年的那次排查花了三个小时,很大原因是信息分散。
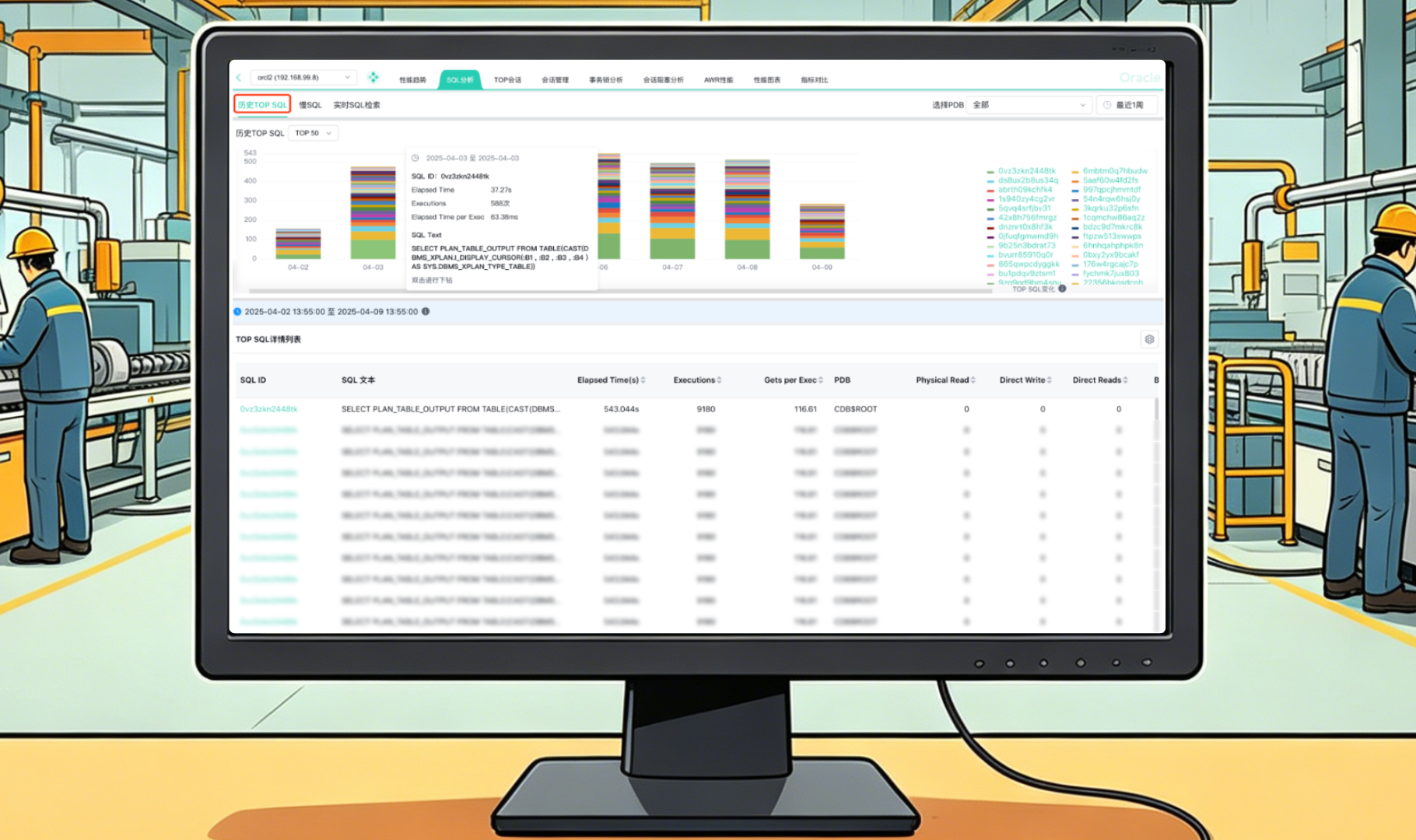
一条慢SQL,可能涉及执行计划、关联等待事件、表结构、索引信息、系统资源占用等多个维度,这些数据搁以前要分别从不同地方捞,再在脑子里拼图。
现在我们利用Bethune X的“一站式SQL分析”功能,输入SQL或者选择一个告警记录,平台就能直接关联好所有上下文:执行计划哪里走了全表扫描、哪个索引失效了、是不是有锁等待、资源瓶颈在CPU还是I/O……不用在多个工具之间来回切换,所有关键信息一目了然。
小周说:“现在排查同类问题,半小时内基本能定位。效率提升了多少不是最重要的,最重要的是心里有底——你知道问题在哪儿,而不是靠经验猜。”
有一次,车间反映某道工序的报工界面响应慢。通过Bethune X分析定位,发现不是网络问题,也不是应用问题,就是一条工时统计的SQL,在某个特定生产批次数据量下,走了全表扫描。改了索引,三分钟见效。
3. 建议要能用:不只是告诉我问题,还告诉我怎么改
分析出问题在哪儿之后,最关键的一步是给出解决方案。
以前DBA排查完问题,还得自己研究怎么改。索引怎么建、SQL怎么改、不同方案有什么风险——这些都得靠个人经验判断。
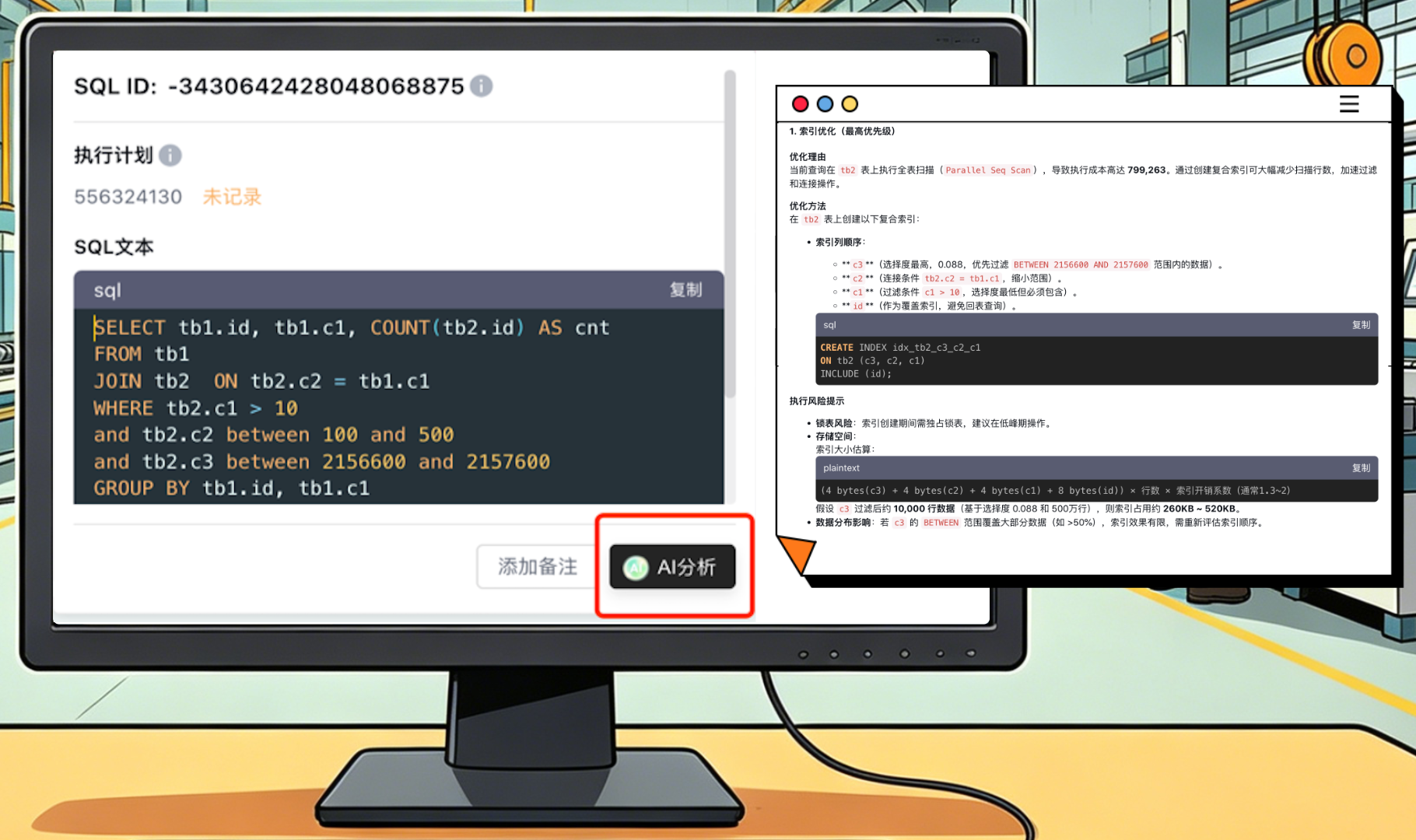
现在是什么时代?AI的时代!Bethune X内置的智能体就能直接给出可行建议,这也是我们非常看重的一点。针对低效SQL,平台会生成具体的优化方案:索引创建会综合考虑字段选择性、表大小、数据分布等因素,不是随便加索引;SQL改写会提供可执行的语句,还会对比不同方案的预期效果。
坦白讲,这些优化建议不是万能的。平台给的是参考,绝大多数情况下是可行的,最终还是要DBA结合实际情况判断。但有了这个辅助,工作量确实小了很多。比如小周,他现在已经习惯先用系统跑一遍建议,再根据自己的判断调整。
对于那些不熟悉的问题,DBA通过平台的智能问答就能查询知识库和同类案例,快速理解优化逻辑,让个人的能力得到快速的专业化提升。
4. 变更要安全:改了不出事,比改得快更重要
前面提过,制造业的生产不能停,所以哪怕是数据库变更也不例外。
不是说不能做变更,而是变更的窗口很小,而且一旦出问题,影响是实打实的产线停顿。
为此,我们对变更流程做了非常严格的管控:
第一,任何涉及索引或者SQL的变更,必须安排在生产间隙执行,提前通知生产计划部门。
第二,变更前要做风险评估:表空间够不够、主备延迟大不大、有没有回滚方案。
第三,变更执行要走完整的审批流程,不能谁想起来就改。
第四,重要变更必须在测试环境先跑一遍,验证有没有异常。
流程看起来复杂且刻板,但确实有必要。特别是最后一点,通过将变更方案在模拟真实负载的测试环境中执行,并利用Bethune X等工具,观察系统是否出现新的Top SQL、异常等待事件或资源使用波动等潜在问题,可以帮助DBA识别变更可能带来的隐藏风险,从而在正式上线前进行调整与优化。所幸自Bethune X上线以来,没出过数据库变更方面的问题。

5. 效果要验证:改了不等于改好了
以前我们有个习惯,SQL改了、表结构调了,如果系统没报错,就默认“改好了”。后来发现并不是这样。
有些优化短期有效,但随着数据量增长或者业务逻辑变化,性能会慢慢衰减。还有些优化解决了A问题,但引入了B问题,只是B问题当时没显现。
所以我们现在有个不成文的规矩:变更完成后,第一时间对比关键指标——查询响应时间、资源消耗、业务接口的响应延迟等,都要和改之前的数据做对照。
DBA借助Bethune X可以把重要SQL纳入重点关注列表,平台就会自动追踪性能趋势。有衰减苗头就告警,不用等到出问题才感知。持续监控让优化效果有据可查,改前改后一目了然。
小周还把一些验证有效的优化规则整理成文档,沉淀到团队知识库里。下次遇到类似问题,直接有据可查。Bethune X可迭代的私域知识库就为我们团队运维能力的提升提供了重要保障。

写在最后
说到底,今年最大的变化不是工具,是思路。
以前是“出了问题再解决”,现在是“提前发现问题、精准解决问题、持续跟踪效果”。数据库这东西,永远有不确定性。但至少,现在大部分时候,我们知道问题在哪儿、知道怎么处理、知道改完之后效果怎么样。
对于制造业的IT团队来说,这种确定性很重要。生产系统讲究的是稳定,而稳定背后,往往是一套靠谱的运维体系在支撑。