前言
据IDC预测,2025年全球数据总量将突破175 ZB,其中实时分析、AI推理和高并发事务处理的需求占比超过60%,而性能不足的基础设施可能导致企业损失年均增长27%,突破传统数据库性能边界已成当务之急。
传统数据库解决方案往往陷入两难:单机数据库受限于硬件容量天花板,分布式数据库又因分布式事务延迟难以满足OLTP严苛要求。云和恩墨推出的多元数据库一体化承载平台 zData X 通过自研分布式存储引擎 zStorage 与数据库深度协同,在保证ACID事务特性的同时,将OLTP场景的P99延迟压缩至微秒级,重新定义高性能数据库的边界。
为什么数据库需要专用分布式存储?
作为多元数据库一体化承载平台,zData X 的设计理念源于对行业痛点的深度洞察。为了满足OLTP场景下的数据库高性能承载,云和恩墨团队对 zData X 底层存储系统的选择慎之又慎,然而,现存开源存储方案存在三大瓶颈:
1. 随机读写延迟波动大:如今的OLTP业务涉及的并发事务处理每秒数千上万笔,这对数据库的时延要求极为苛刻。而基于 Ceph 等传统分布式存储构建的存储层因元数据依赖RocksDB、Compaction写放大等问题,延迟波动可达1-3毫秒,无法满足业务高峰期需求。
2. 扩展性与一致性不可兼得:传统方案若通过增加节点提升IOPS,需牺牲强一致性(如Ceph默认采用最终一致性),若保证一致性,则吞吐量受限,这对金融交易等场景不可接受。
3. 硬件性能利用率低下:如今的NVMe SSD单盘IOPS达百万级,RDMA网络延迟降至微秒级,但开源存储的设计还停留在应对机械硬盘(HDD)的时代,其内核协议栈、锁竞争等问题,实际硬件利用率不足40%。
为数据库而生的存储引擎zStorage
为了保证数据库的高性能承载,高效支撑OLTP业务,云和恩墨最终选择自研分布式块存储系统 zStorage 来支撑 zData X。在如今的新硬件时代,zStorage 在设计之初便选择了一条“彻底拥抱硬件革新”的技术路径,针对数据库场景,利用新兴技术重构存储架构,释放全闪存硬件的极限性能。具体采用的技术手段如下:
1. 用户态
zStorage 的核心代码几乎都运行在用户态,特别是关键的 IO 路径代码,如 Frontend 和 ChunkServer,都是用 C 语言实现的。在用户态开发有诸多好处,不仅能简化调试难度,还提升了系统整体的稳定性,即使某个组件异常退出,zStorage 的守护程序 Keeper 会自动重新启动异常退出的程序,而且由于采用了三副本的架构,不会导致服务停止。
从性能角度来看,完全在用户态开发可以避免用户态和内核态的上下文切换,从而提高性能。此外,zStorage 的编码规范不允许在 IO 请求处理主路径上调用系统调用,这样做旨在减少上下文切换和线程阻塞,进而实现高性能设计。
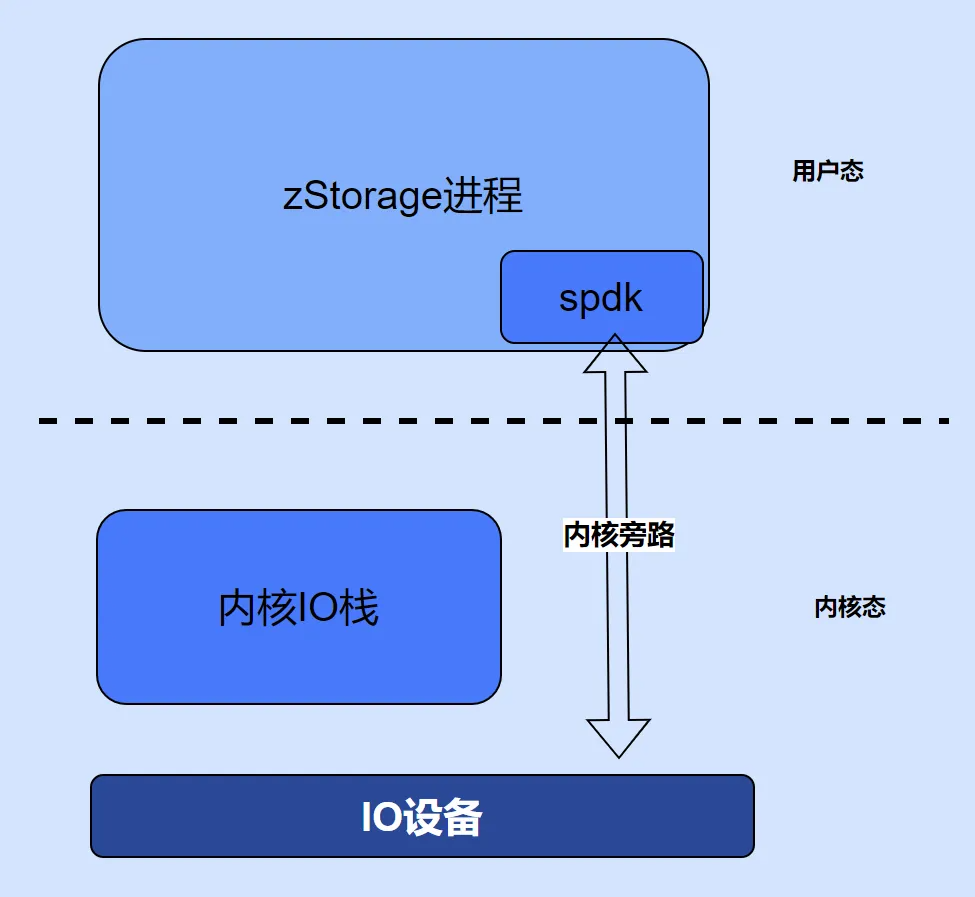
2. 轮询模式和用户态驱动
传统的设备驱动通过触发中断事件与应用交互,在曾经的机械硬盘和普通以太网卡时代,中断处理机制并不是性能瓶颈。然而,在高性能 NVMe SSD 和 InfiniBand RDMA 高性能网卡面前,中断处理机制的性能开销变得不可忽视。同时,传统的设备数据读写需要通过 Linux 内核栈的层层处理,其间还伴随着内存拷贝等动作,这些在 NVMe SSD、RDMA 网卡等高性能设备上的性能损耗,使得硬件设备不能发挥出其真正的性能水平。
zStorage 依赖 SPDK 实现的用户态驱动,如 NVMe、NVMf、iSCSI 等,加快了开发进度。这些用户态驱动结合轮询模式,不等硬件设备的中断消息,不断地去询问硬件设备 IO 请求是否完成,一旦 IO 请求完成,可以第一时间得到处理。这种轮询的线程模型,不仅避免了设备中断,绕过了内核驱动,还抛弃了传统的线程池模式,避免了线程过多带来的线程切换的性能损耗。
此外,zStorage 还支持轮询和中断自适应模式,在 IO 请求负载压力小的时候,使用中断模式,降低 CPU 耗电;在 IO 请求负载压力大的时候,自动切换到轮询模式,最小化性能开销。这种设计更加符合高性能 IO 设备的性能特点,是实现高性能的重要架构选择。
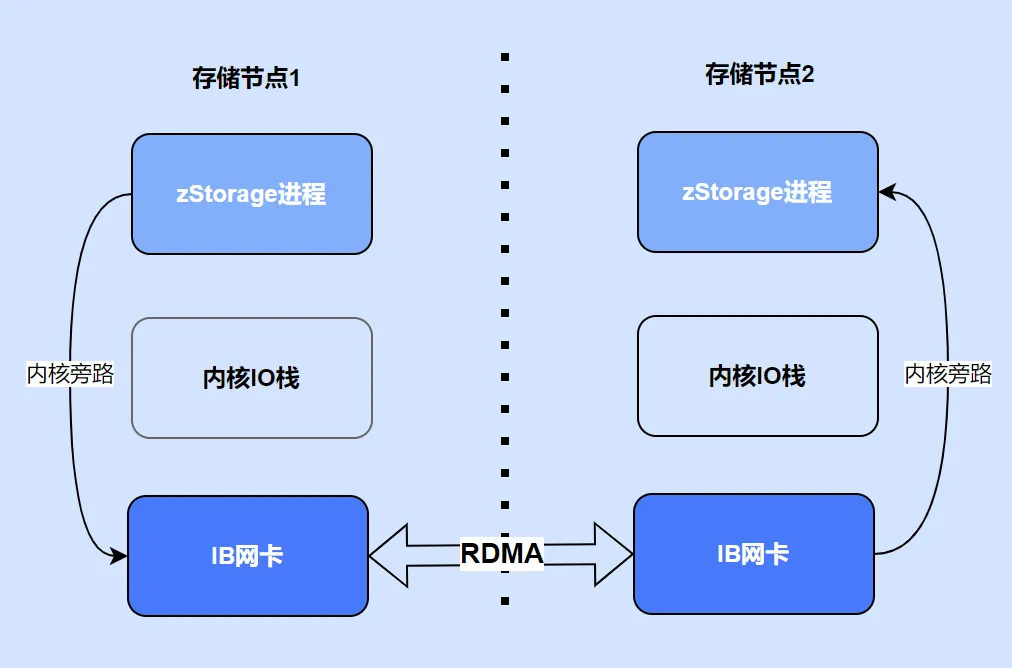
3. RDMA
RDMA 技术是 zStorage 提升性能的又一关键因素。RDMA 技术绕过系统内核,直接将数据写入远程计算机内存。传统网络传输需要数据从应用程序内存经过内核缓存区再发送,远程接收端同样需要经过内核数据拷贝,而且网卡接收数据后通过中断通知 CPU,处理数据成为性能瓶颈。而 zStorage 采用的轮询模式和用户态驱动绕过了操作系统和中断模式的性能问题,以轮询模式在用户态接收数据,充分利用了 RDMA 网卡性能优势,全面采用 RDMA 网络通信解决了 IO 路径上的性能问题。
4. NVMf
在用户主机上,zStorage 不仅支持 iSCSI 协议,同时也支持性能更高的 NVMe over Fabrics(NVMf)协议。NVMf利用 RDMA 技术,通过网络传输NVMf命令和数据,使得远程主机可以直接访问远程存储设备上的非易失性存储。相比 iSCSI 协议,NVMf具有低延迟、高吞吐量、更好的 CPU 利用率和多路径等优势,进一步提高了 zStorage 的性能表现。
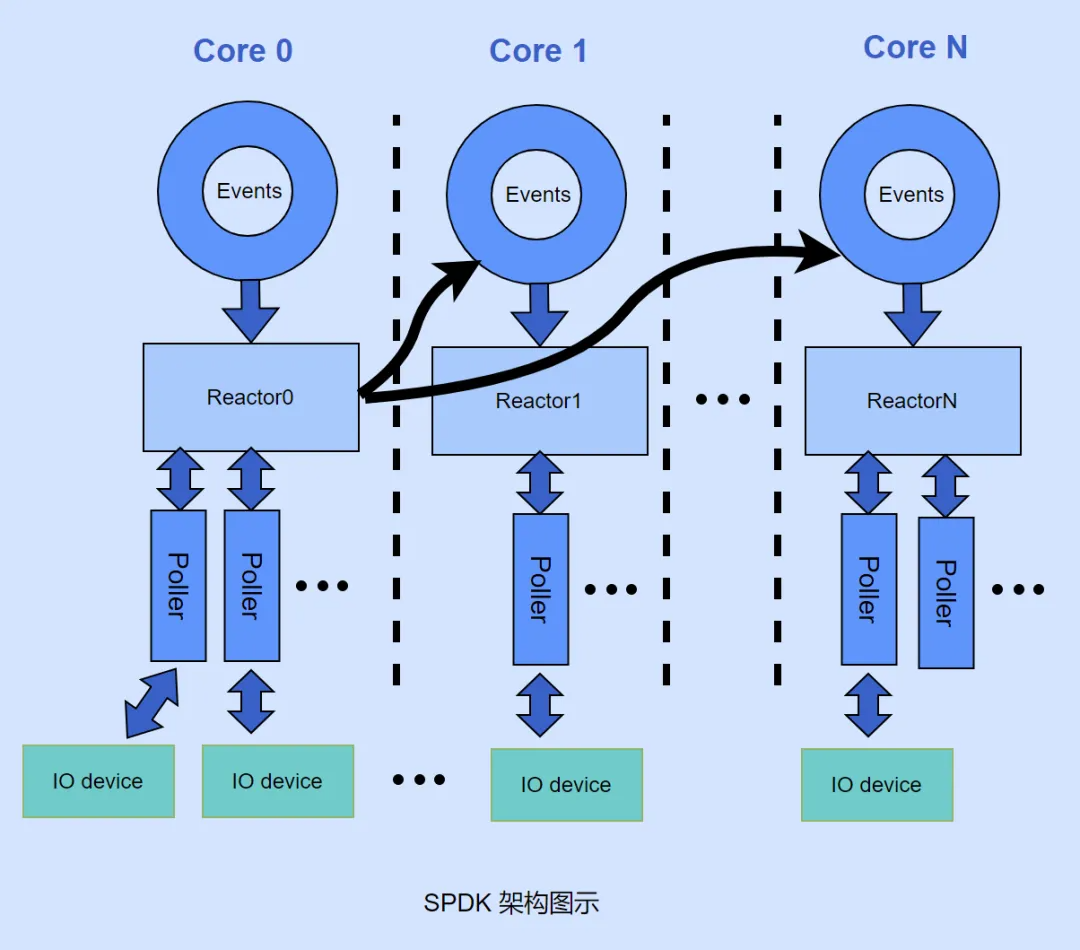
5. 线程模型
zStorage 放弃了传统的线程池模型,采用了异步事件处理模型。在 CPU 性能较弱、机械硬盘性能是瓶颈时,传统线程池模型是有效的。但随着 CPU 和硬盘性能的提升,多线程模式成为性能瓶颈。在异步事件处理模型中,每个 CPU 核心上启动一个线程,不断轮询运行,调用注册到当前线程的 poller 函数。这种模式要求 poller 函数不能阻塞 CPU,因此网络接口采用 socket API 的非阻塞模式。这种编程模型避免了线程切换和阻塞,在 IO 请求负载比较大的情况下,浪费在处理线程上下文切换的 CPU 性能更少,更多 CPU 性能用于用户 IO 请求。
6. 无锁
为了配合异步事件处理模型,zStorage 采用了无锁化编程。无锁化编程有诸多好处,它避免了线程陷入等待、上下文切换以及线程之间竞争带来的 CPU 性能损失。在无锁化编程中,有以下几种情况需要避免:
-
显式的锁操作,如mutex、spinlock等。
-
原子操作,即使相比于锁,原子命令在性能上更优,但仍然会对性能产生一些影响。
-
不必要的缓存一致性操作,例如False sharing。举例来说, 假设有20个线程,每个线程只读写自己对应的一个数组元素,但由于CPU加载缓存时按cache line(64字节)为 单位,即使只修改了线程对应的元素,也会影响到整个cache line,导致相关联的CPU核重新加载cache line。
zStorage 在软件架构中充分考虑到了这些因素,在数据结构的设计上完全适应了无锁化操作。
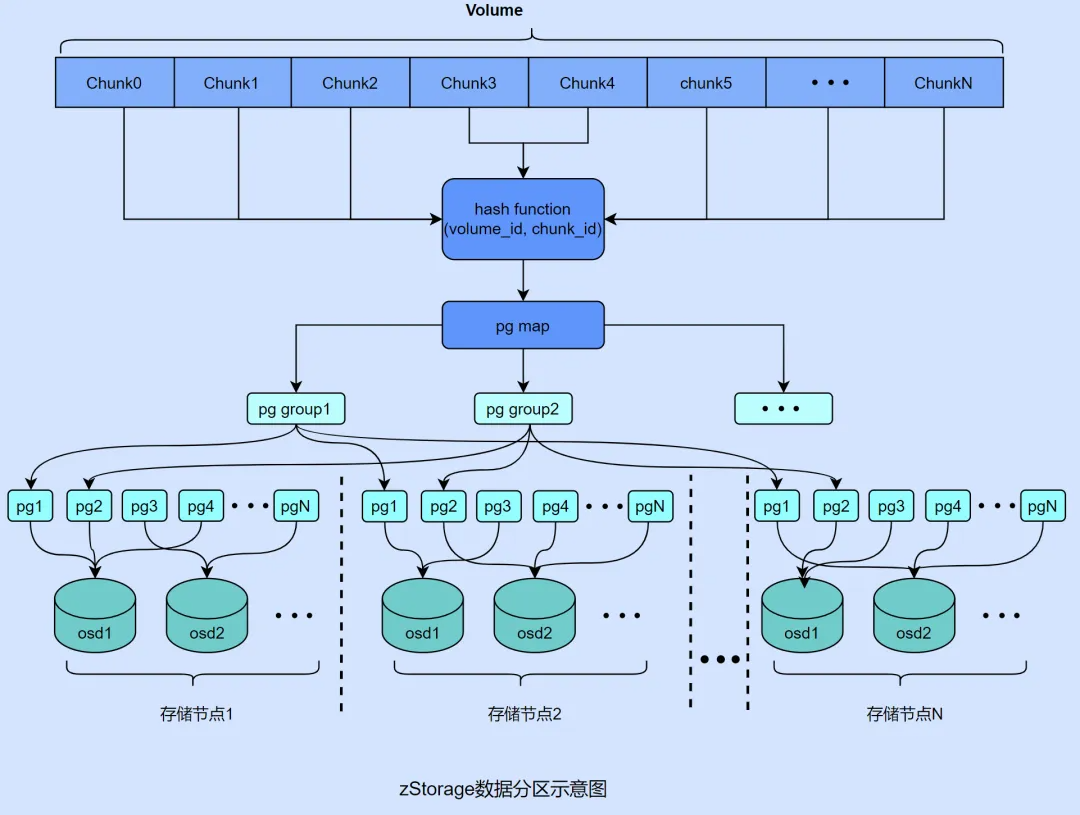
7.数据分区
zStorage 的数据分区结构经过精心设计,以配合异步事件处理模型和无锁化编程。其核心思想是将数据均匀地分布在各个硬盘上,并分配给不同 CPU 核处理。
zStorage 采用了存储池和 PG 的概念,一个存储池包含多个 PG(例如 1024 个),然后通过改进的 CRUSH 算法将 PG 映射到各个硬盘上,基本保证了各个硬盘上 PG 数量的均匀分布。
接着,将卷按照 4MB 为单位划分为多个 Chunk,并根据卷 ID 和 Chunk ID 将 Chunk 映射到某个 PG 上,保证了每个 PG 内存放了同样多的 Chunk。
不过,对于单流顺序读写模式存在一个问题:在某个时刻,IO 负载只会落到某一个 Chunk 上,无法发挥存储节点的多核、多盘的并发能力。因此,zStorage 采用了条带化的方法,将多个 chunk 组成一个类似 RAID0 的条带组,使得顺序 IO 也能利用存储节点的并发处理能力,提升整体吞吐量。
8. 负载均衡
以 “数据分区” 设计为基础,zStorage 在各个 IO 处理环节尽可能实现了 “负载均衡”。这样做的目的是确保各个部件对 CPU、网络和硬盘的使用都能并发进行,防止因为 IO 负载在某一部件上堵塞而导致性能瓶颈。主要的 “负载均衡” 环节包括:
-
确保 HOST 到存储节点的链路负载均衡,保证每个存储节点承担的 IO 负载相近;
-
在存储节点内部的进程(例如 ChunkServer 和 Frontend)中,实现 IO 负载在各个 CPU 核心上的均衡,充分利用 CPU 的处理能力;
-
Frontend 将 IO 请求均衡地发送到 ChunkServer 的对应 CPU 核心上,减少额外的线程投递,提高处理效率;
-
在存储节点及硬盘之间实现 IO 负载均衡。
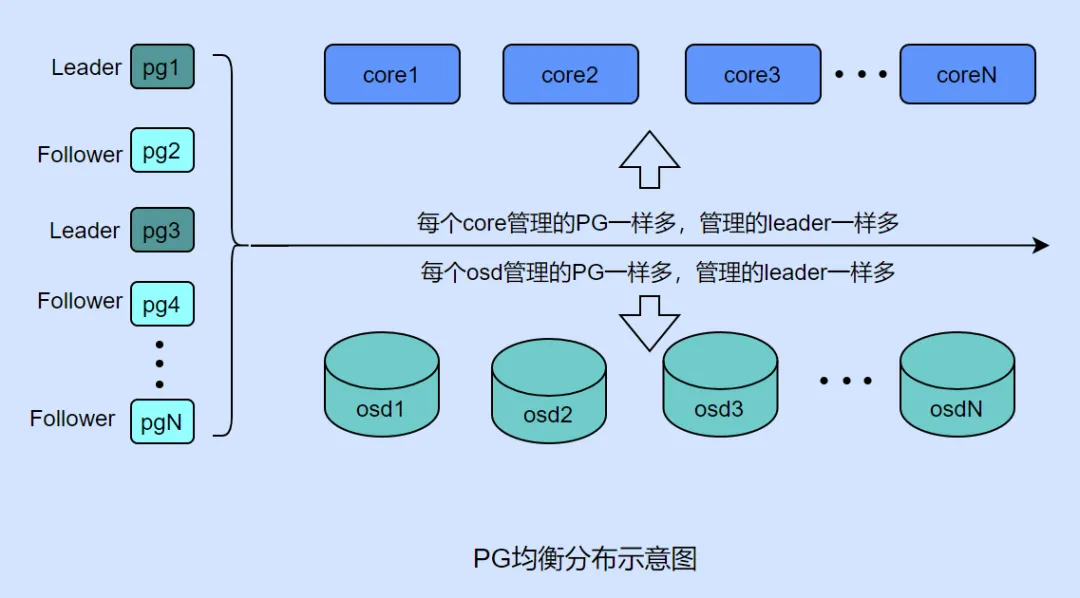
为此,zStorage 实现了 PG 以及 PG leader 在 CPU 核心和硬盘之间的均衡算法,确保在节点间、CPU 核心和硬盘之间都能实现负载均衡。这些 “负载均衡” 策略是 zStorage 高性能架构设计的关键技巧之一。
9. 本地存储
zStorage 在设计之初,还考虑到 Ceph 等系统存在的本地存储问题。例如,Bluestore 使用 RocksDB 存储元数据,由于 Compaction 导致的写放大,在某些情况下可能高达20 倍;并且RocksDB 的性能开销不容忽视,特别是它的事务带来的开销更大。
为了解决这些问题,zStorage 设计了自己的 LocalStore 模块。元数据采用哈希索引结构,大部分场景下,可以在内存元数据 Cache 中命中。而用户数据不做缓存,每次都直接读写物理盘。这种设计大大减少了每次 IO 的元数据读取,尤其是小 IO 操作,从而提升了性能。由于 zStorage 所采用的是高速 NVMe SSD 硬盘,只需少量盘即可实现高 IOPS,因此系统不再对用户数据做缓存,而是直接落盘,旨在减少用户数据无关的 IO,充分发挥物理硬盘的性能。
以架构革新重构数据库性能的底层逻辑
zData X 的高性能,源于其底层分布式存储引擎 zStorage 对数据库场景的深度适配。zStorage 通过对数据流每一个环节的极致优化,用更短的IO路径、更少的无效指令、更精准的资源调度,释放新硬件本应有的潜力。
当前测试数据显示:zStorage 的在研版本在三个存储节点配置下,4K混合随机读写(7:3)已经达到了300万IOPS,平均时延300μs,P99时延800μs。随着 zStorage 团队的不断优化,未来将持续冲击400万、500万IOPS。
如今,搭载着 zStorage 的 zData X 已经服务超过200家金融、制造、医疗、交通等行业客户,其解决方案获得多个行业大赛奖项。可以预见,随着 zStorage 性能的进一步提升,zData X 将在更多领域展现出强大的竞争力,助力企业实现数据库效能的高速跃升。