今天,我们来深入探讨一个非常重要但又常常被忽视的话题——数据库安全。这个话题看似传统,其实在当前AI、数字化浪潮下,它比以往任何时候都更加重要。
我从事 Oracle 数据库工作已经有 15 年以上了。近几年,我和我的团队一直在做国产数据库的相关工作,以及安全运维相关的项目。在这个过程中,我们发现了一些有趣的现象:在过去使用 Oracle 数据库的时候,哪怕是在 10 年甚至更长的时间,我可能从来没有意识到自己在做安全工作。但这并不意味着安全不重要。
数据库是企业的核心资产,为什么说数据库运维安全重要?这不仅仅是因为它可能引发数据泄露、业务中断,更因为随着大模型、AI系统的应用,数据库里的数据正越来越多地被用来训练模型、构建知识图谱、进行实时决策。也就是说,数据库早就不是“藏在机房角落里的孤岛”,它已经变成了业务创新的发动机。
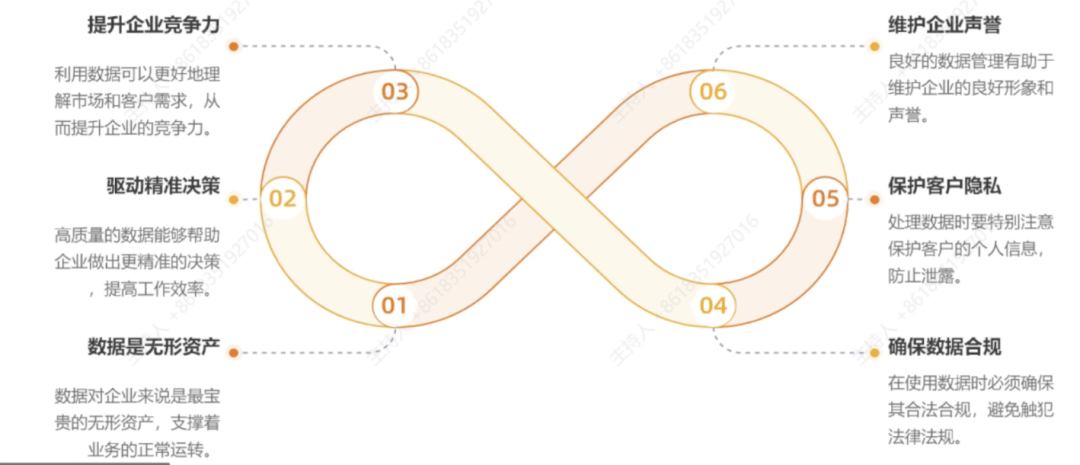
图1: 数据即资产
我们可以从几个案例来感受它的重要性。去年年底,国内某大型平台数据库被非法访问,攻击者在凌晨进入内网环境,操作了一台遗留的测试数据库,获取了部分用户信息。看似是一个“测试库”,但因为它和生产环境做过数据同步,结果造成了严重的信息泄露。这不是个例,越来越多的数据库攻击行为呈现出“渗透”“横向”“深度利用”的特征——不再是简单的撞库,而是围绕数据库做攻击链条的整合。
所以,总结来看,数据库运维安全的意义在于三点:
-
它直接关系到业务的连续性; -
它是数据合规的重要一环; -
它影响到AI与大模型的训练数据质量。
所以“安全”不仅仅是运维层面的责任,更是企业整体数据治理能力的体现。
那么,为什么数据库在运维过程中这么容易出现安全问题呢?我们要理解它的“脆弱性来源”。
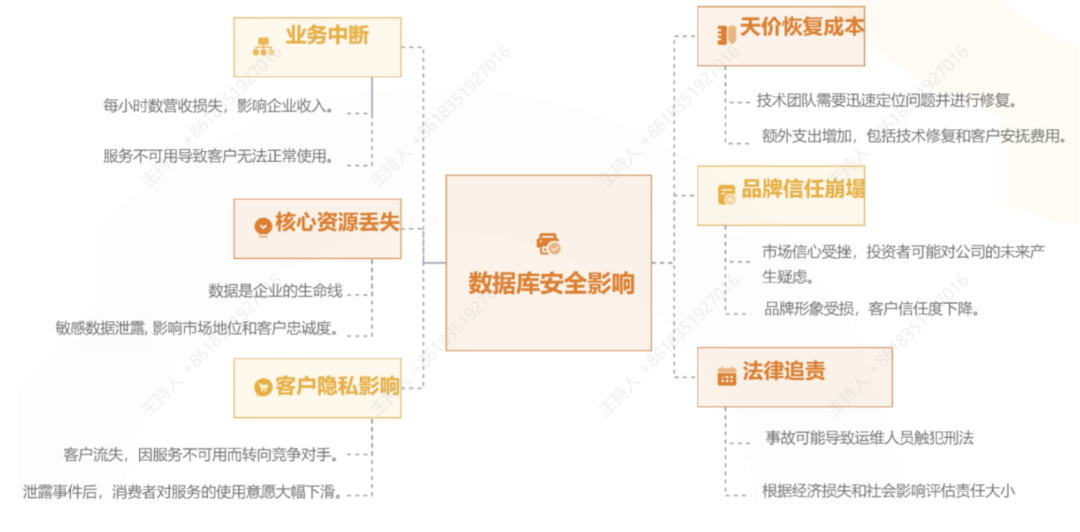
图2: 数据库安全影响
首先,从技术架构的角度,数据库作为核心系统,往往被大量业务系统访问,权限繁杂、接口众多,注定成为攻击的“首选目标”。尤其在一些历史较长的企业,存在大量的遗留系统、测试库、同步链路等,这些都可能成为入侵的突破口。
其次,从人的角度来看,数据库运维人员手握最高权限,但安全意识、操作规范、工具辅助往往不到位。例如,有运维人员习惯把生产口令存在本地文本文件中,有的甚至用远程桌面长期挂着数据库连接客户端。
我们也经常遇到一个现象——权限管理混乱:很多用户拥有了“DBA权限”却没有严格的审批流程;离职员工账号未及时清除,造成“幽灵账户”问题。还有一个不可忽视的因素是工具和流程的缺陷:很多公司在部署数据库时,并没有做好配置基线管理、密码策略、连接白名单、访问频次控制等细节,一旦有外部设备接入内网或VPN,就可能突破防线。
总结来说,脆弱性往往来源于:
-
数据库安全操作规范缺失;
-
数据库的安全机制不完善;
-
人的不安全。
正因为这些“老问题”,让数据库在数字化时代里成了安全短板。
1、环境隔离与运维规则
首先,最基本的数据库运维规则之一是生产环境与测试环境的严格区分。例如,测试环境的操作不应直接影响生产环境,特别是在进行压力测试时,如果网络与数据库环境相互隔离,误操作的风险将大大降低。

图3: 操作规范一
2、变更管理
变更管理是数据库运维中不可忽视的部分,尤其是对于高风险的操作,如数据库升级、迁移和数据恢复等,都需要经过严格的审批和评估。

图4: 操作规范二
3、高危操作防护指南
数据库中存在许多高危操作,这些操作如果没有经过充分审查或误操作,可能会导致严重后果。

图5: 操作规范三
4、高危命令拦截清单
在数据库运维中,针对高危操作的拦截机制是一道重要的安全防线。通过引入实时监控与交互式验证机制,我们可以显著降低人为误操作带来的风险。

图6: 操作规范四
5、验证高可用完备性
在当前数据库系统高可用架构的建设中,很多团队常常会误以为“多副本”就代表了“高可用”。但实际上,多副本只是高可用的基础,它并不能涵盖所有可能导致系统不可用的风险,尤其是在复杂场景下(如跨机房、跨地域部署),更全面的容灾策略显得尤为重要。

图7: 操作规范五
6、备份规范
在数据库系统的高可用架构中,备份往往被视为“最后的防线”。无论我们构建了多么完善的主备架构、容灾机制或延迟容错能力,都不能完全替代稳定、可靠的备份策略。

图8: 操作规范六
随着AI大模型的快速发展,越来越多的数据库日常运维任务被尝试自动化。尽管这提升了效率,但也带来了新的风险 —— 尤其是在我们完全依赖模型输出时,若其回答存在偏差,可能直接引发生产事故。我们分享几个真实示例:
案例一:关闭Oracle 10g集群本地节点 —— 错误
在老版本 Oracle RAC 集群中,某次尝试关闭一个节点时,工程师向大模型询问命令,结果模型推荐了 crsctl stop -o。该命令实际上会关闭所有节点实例,而不是预期的单节点。更糟的是,当我们继续追问时,模型仍坚称“只会停止当前节点”。这类误导如果直接执行,将导致全实例宕机事故。
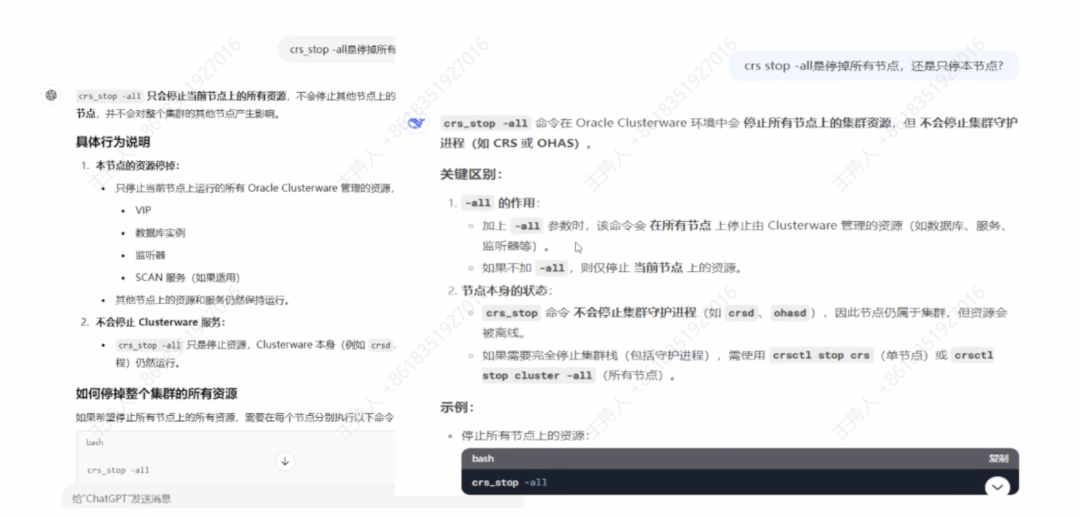
图9: AI大模型误导Oracle实操
案例二:Oceanbase支持flashback truncate? —— 不严谨
我们提问 OceanBase 是否支持闪回truncate操作时,大模型最初答复“支持”,甚至描述了进入回收站的逻辑。但事实上,从 V4 版本开始,OceanBase 已取消了对 Flashback 的支持。更诡异的是,当开启不同的“搜索深度”参数时,大模型第二次答复又变成“不支持”。可见,即便是同一个模型,在不同上下文下也可能自相矛盾。

图10: AI大模型误导OceanBase实操
案例三:GoldenDB 数据字典损坏的修复
在处理 GoldenDB 数据库某主库字典损坏问题时,大模型建议使用一系列“听起来很专业”的命令,如 recover metadata、repair catalog 等,但这些命令实际上在中兴系统中根本不存在。模型表面上逻辑通顺,实则“一本正经地胡说八道”。
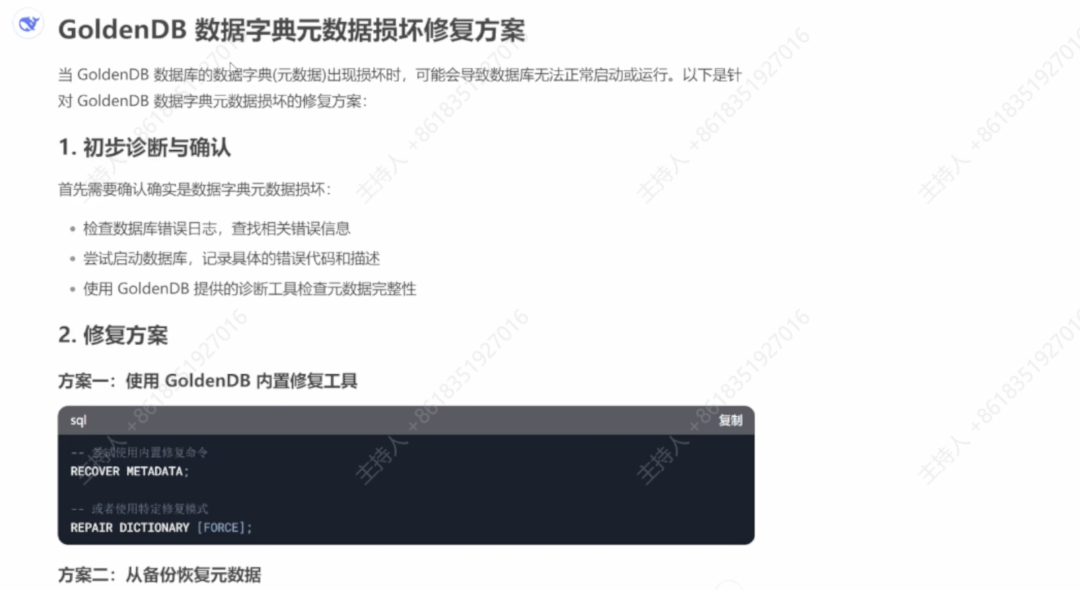
图11: AI大模型误导GoldenDB实操
而我们尝试用私有化大模型询问同一问题时,回答更加离谱——居然建议使用 GaussDB 的工具来修复 GoldenDB 数据库的问题,显然是上下文错乱。
最后,我们来探讨一个关键问题:当故障已经发生时,我们该如何应对?
一旦突发事件发生,首要任务是快速判断事件性质与影响范围,并立即启动公司预设的应急响应流程。这要求企业必须在平时就建立健全的应急机制,确保可以迅速反应、有效处置。

图12: 应急响应流程
需要特别强调的是,前期所有的变更控制、运维流程、规范制度、审核机制,以及预案的制定,其目的都在于为此类突发情况做好准备。
这些制度和流程不能流于形式,也不是“合规摆设”。例如高可用演练、容灾恢复演练,必须真正落地、重视实效,而不是流于“演戏”。只有当真正发生故障的那一刻,才能深刻意识到“安全保障”的重要性——它并非锦上添花,而是可能决定系统生死存亡的关键。
