
00.
序章:华人先知点燃的火炬

01.
檄文:数据库机来了

萧开美在论文中回顾了数据库机技术的发展,并满怀热情地呼吁数据库机的时代已经到来。这篇论文被视为数据库机领域的“动员令”和“战斗檄文”。
值得玩味的是,这篇论文的标题中,"Data"和"Base"是两个独立的单词,而非我们今天熟知的合体词"Database"。这个小细节,折射出那个时代技术词汇尚未定型的历史语境——Database作为单一词汇的通用化,本身就是1980年代以后的事情。
萧开美论文的核心论点可概括为:新兴研究的持续发力与硬件技术的最新进展,将很快使商用数据库机成为现实。这一论断包含三层内涵:
第一,技术就绪性判断。萧开美指出,大规模集成电路、半导体存储器、微处理器等硬件技术的进步,已使构建成本可控的数据库专用硬件成为可能。
第二,研究生态成熟度判断。论文强调数据库机并非孤立的硬件创新,而是需要数据库理论、体系结构、算法优化等多领域研究的协同推进。
第三,商业化前景预期。论文明确指向商业数据库机,而非纯粹的学术研究原型,体现了作者对技术转化路径的清晰认知。
从技术架构角度,萧开美论文虽未展开详细设计,但指明了数据库机的核心特征:将数据库操作从通用CPU卸载(offload)至专用处理单元,实现存储与计算的协同优化。这一思想成为后续所有数据库机/一体机设计的根本遵循。
同年6月,萧开美又发表了配套论文《DBC——一台为超大型数据库设计的数据库计算机》(DBC—A Database Computer for Very Large Databases)5,进一步探讨了数据库机的架构与设计方案。
在20世纪70年代末到80年代初,数据库机之所以成为热点,是因为随着数据量的指数级增长,通用计算机的CPU逐渐成为处理大规模数据库任务的瓶颈。萧开美通过研究提议:“既然通用计算机慢,那我们就为数据处理量身定制一套硬件。”
1983年,萧开美主编出版了《高级数据库机架构》一书,系统总结了该领域的各种技术路线,指明了数据库机前进的方向,成为那个时代数据库机研究者的重要参考。正是这本书,在数十年后出现在史忠植访谈画面里,再度唤起了我们对这段历史的记忆。
4 David K. Hsiao, "Data Base Machines are Coming, Data Base Machines are Coming!", ACM SIGMOD Record, Vol. 9, No. 4, March 1979.
5 David K. Hsiao, "DBC—A Database Computer for Very Large Databases", VLDB Conference Proceedings, June 1979.
02.
行动:数据库机的商业化如火如荼
萧开美关于数据库机的研究论文影响了很多人,杰克·谢默(Jack E. Shemer,1940-2020)是其中之一。谢默曾在施乐工作,在看到萧开美的文章后,他相信数据库机的时代即将到来。1979年7月,谢默联合几位来自施乐和花旗银行的资深技术专家创立了Teradata。Teradata在大规模并行数据处理领域做出了革命性的开创工作。后来,Teradata成为了VLDB的长期赞助商。
萧开美还曾为另外一家数据库机公司——布里顿-李(Britton-Lee)——提供咨询。关于Teradata和Britton-Lee的故事,读者可以参考前面的文章——
《从Teradata到Exadata和zData的容量愿景》
《从Britton-Lee的陨落到Exadata和zData的智能复兴》
《从Britton-Lee到zData,专用硬件和通用硬件之抉择》
03.
批判:一篇让数据库领域颤抖的论文
1983年,一篇措辞犀利的学术论文在数据库机领域引发了轩然大波。这篇论文的作者,是来自威斯康星大学麦迪逊分校的戴维·德维特(David J. DeWitt)——日后的并行数据库系统权威、数据库学界最具影响力的学者之一。
论文的标题极为直白,充满挑衅意味:《数据库机:一个已经过时的构想?——对数据库机未来发展的批判性分析》(Database Machines: An Idea Whose Time has Passed? A Critique of the Future of Database Machines)6。要知道在几年以前,德维特还是数据库机的坚定支持者,他和保拉·霍索恩(Paula Hawthorn)的合作直接影响了Britton-Lee的创立和发展。然而短短几年之后,德维特对数据库机的看法就发生了转变。
文章开头,德维特写道:“萧开美撰写《数据库机来了》一文时,数据库机的前景似乎一片光明,许多研究项目正在进行,几款商业产品也即将面世。然而现在我们的观点完全不同,我们曾一度想将本文标题定为‘数据库机死了(Database Machines are Dead, Database Machines are Dead)’”。
这种呼应萧开美论文标题的刻意反转,颇具文学色彩,也让这篇批判性论文获得了更广泛的传播。
6 Haran Boral, David J. DeWitt, "Database Machines: An Idea Whose Time has Passed? A Critique of the Future of Database Machines", IWDM 1983: 166-187
德维特的核心观点是:磁盘容量的增加对高度并行数据库机产生了非常不利的影响,除非找到提高大规模存储设备带宽的方法,否则高度并行的数据库机架构注定要消亡。
这个论断在当时颇有说服力。专用数据库机的硬件成本高昂,而通用计算机的性价比则在摩尔定律的驱动下快速提升。专用硬件的优势,正在被通用硬件的迅猛进化所侵蚀。
然而,德维特本人并未就此放弃。批评者往往也是探索者——在发表那篇批判性论文的同一年,他在威斯康星大学悄悄启动了一个全新的研究项目:Gamma数据库机项目7。
Gamma项目从1984年1月正式启动,持续运行到1992年底。其核心目标,恰恰是去验证德维特在1983年论文中所质疑的东西:使用非专用的通用(“廉价”)硬件,能否实现高性能的并行数据库系统?
Gamma运行在一个由普通工作站通过高速网络互联而成的集群上,采用无共享(Shared-Nothing)架构,通过数据分区(Partitioning)和并行查询处理实现高性能。它证明了一个关键命题:并行数据库不一定需要专用的昂贵硬件,通用硬件的集群同样可以实现出色的性能。这一发现,深刻影响了此后整个并行数据库系统的发展方向。
时间来到1992年,德维特与吉姆·格雷(Jim Gray)联合撰文发表了《并行数据库系统:高性能数据库系统的未来》(Parallel Database Systems: The Future of High Performance Database Systems)。在这篇论文中,他们共同反驳了德维特1983年的判断:
高度并行的数据库系统正开始取代传统的大型机,用于超大规模的数据库和事务处理任务。这些系统的成功驳斥了1983年一篇预测数据库机消亡的论文。十年前,高度并行数据库机的未来看起来黯淡无光,即使在其最坚定的支持者看来也是如此。批评者预测,除非找到解决I/O瓶颈的方案,否则多处理器系统将很快受到I/O限制。虽然这些关于硬件未来的预测相当准确,但批评者关于并行数据库系统的整体未来的判断肯定错了。在过去十年中,Teradata、Tandem和许多初创公司成功地开发并销售了高度并行的数据库系统。
德维特作为一位学者公开承认自己十年前的判断“肯定错了”,这在学术界并不多见。德维特和格雷的这篇论文成为并行数据库系统领域的经典文献,也标志着这一方向完成了从“被质疑”到“被认可”的历史性转折。
7 D.J. DeWitt, S. Ghandeharizadeh et al., "The Gamma Database Machine Project", IEEE Transactions on Knowledge and Data Engineering, Vol.2, No.1, March 1990. DOI: 10.1109/69.50905.
04.
复兴:Exadata的谋定而后动
德维特在1983年指出的那个死结——磁盘I/O带宽的增长速度跟不上数据量的增长——并没有消失,它只是被推迟了。时间进入21世纪,这个问题再度以新的形式出现在数据库设计者的面前。
然而,技术的进步也带来了新的解法。到2000年代中期,InfiniBand高速互联技术的成熟,为打破带宽瓶颈提供了一把“钥匙”。InfiniBand是一种高性能、低延迟的网络互联标准,其带宽远高于同期的以太网,延迟则低至微秒级。正是这把“钥匙”,让Oracle等待已久的数据库一体机蓝图成为可能。
当Oracle开始谋划推出数据库一体机时,德维特当年所指出的约束条件都已经有了解决方案。Oracle数据库一体机的目标是通过开放硬件打造高性能的数据库基础设施。

与Smart Scan配合的,是连接计算节点和存储节点的InfiniBand高速内部网络。InfiniBand在Exadata内部同时承担两个角色:其一,作为Oracle RAC(Real Application Clusters)节点间的私有互联网络;其二,作为计算节点与Exadata存储服务器之间的数据传输通道。两个角色都要求极低的延迟和极高的带宽,InfiniBand完美胜任。
这一架构,正是对德维特所预言的“提高大规模存储设备带宽”的工程实现——只不过,解法不是传统意义上的磁盘带宽提升,而是通过高速网络与存储计算下推的组合,在系统层面上规避了带宽瓶颈。
Oracle的第一代一体机产品面向数据仓库场景。很快,在2009年推出的第二代产品,将Exadata的应用场景扩展至OLTP。同时,闪存技术被用来加速I/O,Smart Scan技术则被用来缩减网络流量。一体机开始解除束缚,Exadata进入高速发展期(如图5所示)。
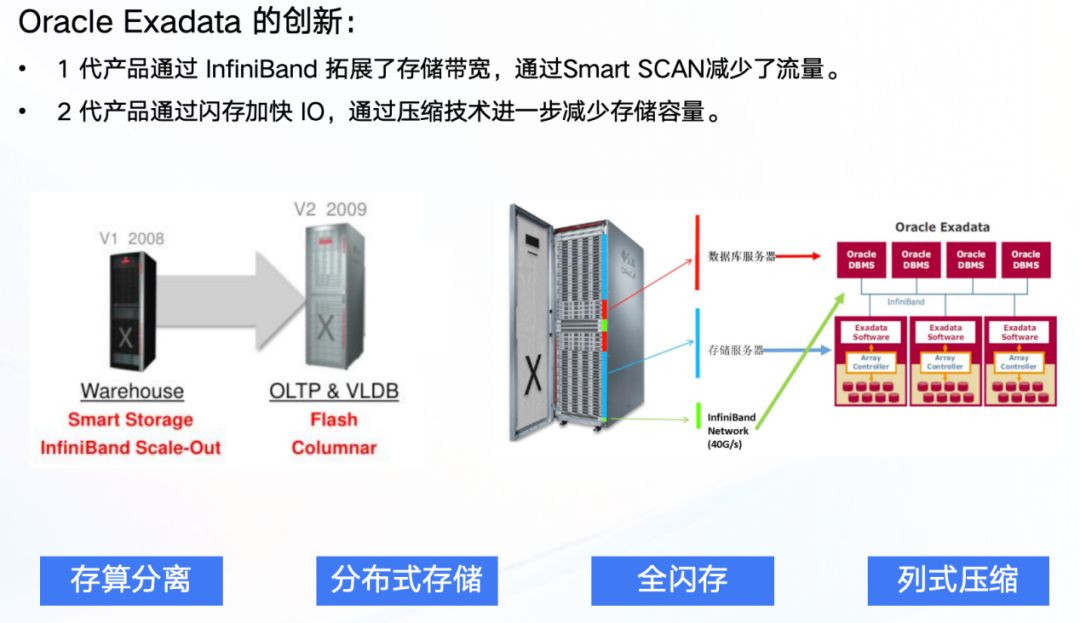
图5 Oracle Exadata的早期创新
Oracle Exadata的成功带动了数据库一体机市场的复兴,很多厂商开始提供第三方的同类产品。但本质上,所谓第三方的“Oracle数据库一体机”是不存在的。因为Oracle并不授权任何第三方一体机预装Oracle数据库。而且第三方一体机需要依赖Oracle ASM才能实现数据冗余和条带化,导致产品竞争力不足。
8 Oracle官方Exadata十年历程信息图,https://www.oracle.com/webfolder/s/assets/infographics/10-years-of-exadata/index.html
05.
革命:软件定义一切带来真正的解放
“数据库机”的真正进化在于软件定义时代的到来。2010年代初,“软件定义”浪潮席卷整个IT产业:软件定义网络(SDN)、软件定义数据中心(SDDC)、软件定义存储(SDS)……这场浪潮的核心逻辑,是将原本固化在专用硬件中的功能,以软件的形式在通用硬件上实现,从而获得更高的灵活性、可扩展性和成本效益。
软件定义存储领域涌现出多个具有代表性的项目和产品:Ceph——由加州大学圣克鲁兹分校博士生Sage Weil于2004年发起的开源分布式存储系统,2012年以LGPL协议开源,2014年被Red Hat收购,被誉为“存储领域的Linux”9;ScaleIO(现更名为Dell PowerFlex)——EMC收购自以色列公司ScaleIO,提供基于服务器的软件定义块存储。
9 Sage Weil,Ceph项目历史,"Ceph: 20 Years of Cutting-Edge Storage at the Edge", The New Stack,InfoQ翻译,2024-10-16,https://www.infoq.cn/article/dfjRxSKdNJtNbqiddwmu
通用的软件定义存储可以支持对象、块存储等,而云和恩墨基于自身的数据库基因,走上了一条与Ceph等通用SDS方案不同的专业化道路:不做通用的SDS,而是聚焦专为数据库场景深度优化的软件定义块存储。这就是zStorage的由来。
zStorage是云和恩墨自主研发的数据库分布式存储软件,针对数据库I/O特征——高IOPS、低延迟、大量随机读写——进行了深度优化,并充分利用现代NVMe闪存和高速网络(InfiniBand和RoCE)的性能潜力。以zStorage为内核灵魂的zData数据库一体机,因而将Exadata的愿景再度向前推进一步:以开放的通用硬件,实现通用数据库的性能加速。
在软件定义存储的数据库部署模式中,传统的“数据库服务器+专用存储阵列”架构被彻底重构:
-
存储资源池化:基于x86标准服务器的分布式存储资源池取代专用存储阵列,存储节点可以独立横向扩展。
-
性能与容量协同扩展:通过节点级横向扩展,使性能与容量同步增长,消除传统集中式架构的性能瓶颈。
-
在线弹性扩容:数据库的扩容完全可以在线进行,无需停机,业务连续性得到根本保障。
-
高速网络加持:25Gb至200Gb带宽的高速RoCE InfiniBand网络,确保存储I/O路径的极低延迟和超高吞吐。
这是技术进步为数据库基础设施带来的根本性革命:数据库摆脱了存储层的束缚,获得了极致性能与极致弹性的双重自由。传统存储架构与软件定义存储架构的对比如图6所示。
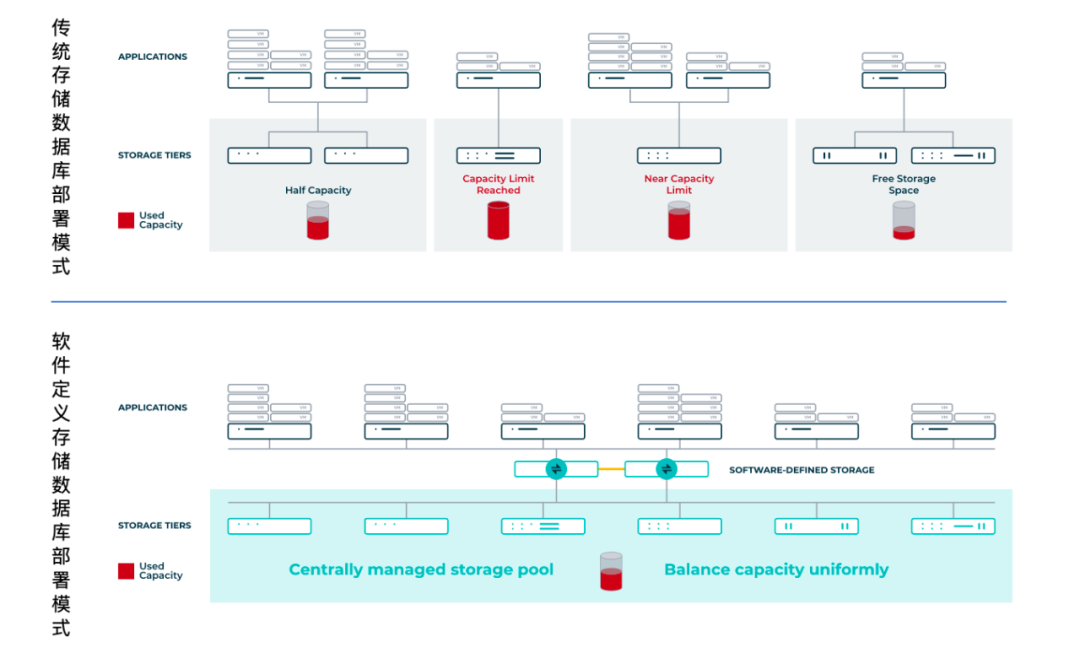
图6 传统存储架构与软件定义存储架构的比较
2025年10月,具备多元数据库承载能力的新一代zData X在金杯电工正式上线,帮助这家传统制造业巨头将其生产制造(MES)、供应链(SRM)、销售(CRM)、财务(ERP)等核心系统整合到新平台之上。系统完成重构迁移之后,数据库I/O性能较原架构提升了10倍,并且从超融合平台回收了148核CPU、17.7TB存储,让用户的资源得以充分利用,整体IT运行成本得到大幅优化。zData X提供的可视化智能运维平台更让数据库管理实现了现代化(如图7所示)。
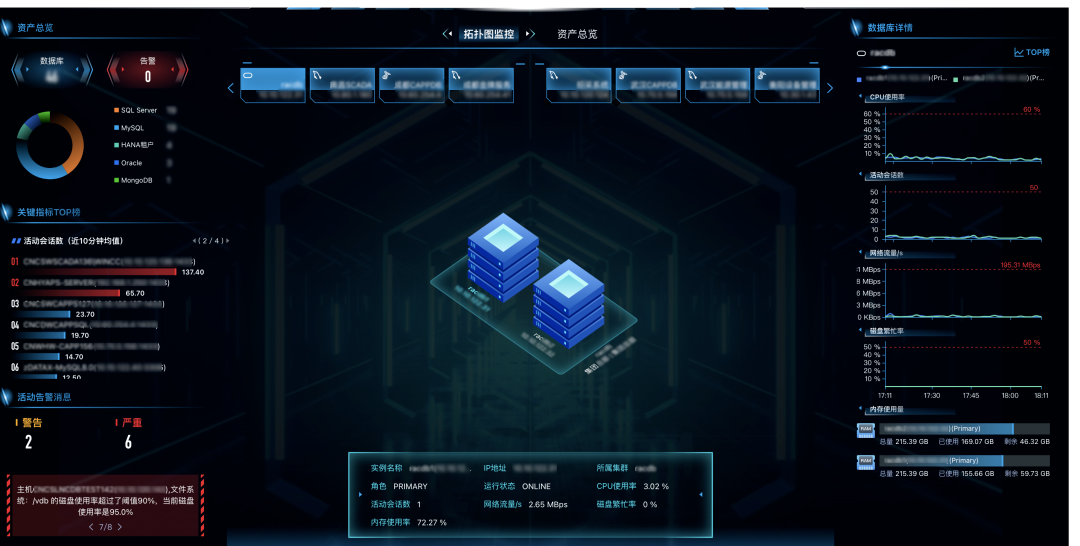
图7 zData X在金杯电工的应用实践
06.
眺望:AI时代数据库机的新轮回
写完这段历史,不能不向前眺望。
当下,人工智能的浪潮正在深刻改写数据库与存储的版图。GPU加速数据库、向量数据库、AI原生数据库……一批专为AI工作负载设计的“新型数据库机”正在悄然涌现。有趣的是,这些新物种的核心思路,与1970年代数据库机研究者们的初衷惊人地相似:为特定的计算特征设计专用的硬件与软件协同方案。
倘若萧开美与德维特能够并肩站在今天,面对这一幕,或许会会心一笑:这场关于专用硬件与通用硬件的辩论,从未真正结束,也永远不会结束——因为它的本质,是人类永不停息地追逐计算极限的冲动。
历史的螺旋,还在转动。
参考文献:
专访史忠植研究员:二十多年前就开始做 Agent 研究的中国学者,InfoQ,2024-12-30,https://www.infoq.cn/news/vAy1biQtrhdHHWJqz97z
《中国数据库40年》,2017.10,清华大学出版社